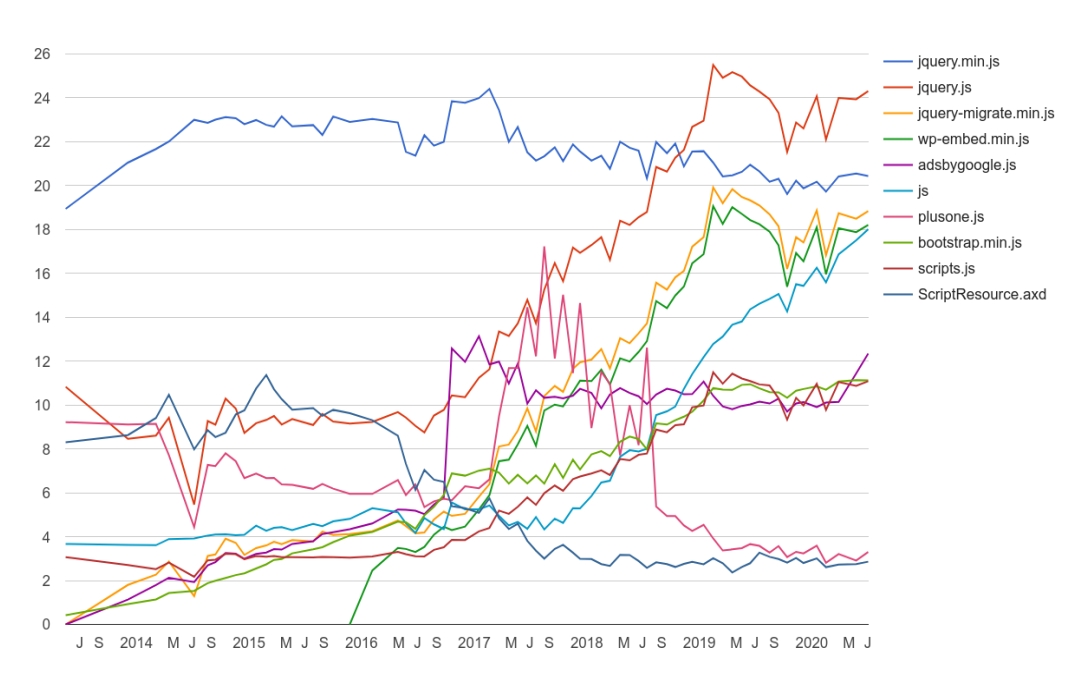
Maschinelles Lernen

 Manöverbeispiel der autonomen Schubkarre anhand einer Z-Marke
Manöverbeispiel der autonomen Schubkarre anhand einer Z-Marke
Im Projekt Autonome Intelligente Roboter entwickeln Studierende in kleinen Teams kreative Robotik- und KI-Anwendungen. Ziel ist die Realisierung autonom handelnder Demonstratoren, die intelligente Funktionen wie Wahrnehmung, Sprachverarbeitung, Planung, Lernen oder Interaktion mit Menschen kombinieren.
Das Smart Dungeons and Dragons Dice System erkennt Dungeons-&-Dragons-Würfel mit selbsttrainierten KI-Modellen und reagiert auf Wurfergebnisse mit Licht, Sound, Text und Bildern. Eine HTML-Anwendung, YOLOv8-Modelle und ein ESP32 mit WLED-Streifen bilden zusammen einen interaktiven Demonstrator. (Hannah Mierzchala)
Starseeker ist ein sprachgesteuerter Sternenzeiger. Sprachbefehle werden mit Whisper erkannt und mit einem LLM ausgewertet; anschließend richtet ein Arduino-gesteuerter Roboter einen Laserpointer auf den gewünschten Himmelskörper aus. (Fasih Uddin, Dilara Ihwe, Johanna Tille)
Der Autonome Aufräumroboter mit Turtlebot erkennt Objekte, die ein Staubsaugroboter potenziell aufsaugen könnte, und positioniert sich selbstständig davor. Dafür werden ein TurtleBot3 Waffle Pi, eine Onboard-Kamera, der OpenManipulator-X und ein selbsttrainiertes YOLOv8-Modell zur Objekterkennung eingesetzt. Ziel ist es, erkannte Objekte autonom anzufahren, zu greifen und auf dem Roboter zu transportieren, sodass der Boden für den Einsatz eines Staubsaugroboters freigeräumt wird. Das System konnte Objekte zuverlässig erkennen, verfolgen und sich mittig davor ausrichten.(Maike Maehs, Guillia F. Jiokeng Noutcha)
Z.E.D. – Die Autonom Fahrende Schubkarre ist ein Transportroboter, der einen durch künstliche Landmarken markierten Weg autonom abfährt. Optische Sensoren erkennen die Landmarks, eine IMU unterstützt die Kursstabilisierung, und ein ESP32-Dualcore-Mikrocontroller trennt Sensorverarbeitung und Aktionsplanung. Ziel ist ein nützlicher Demonstrator für Transportaufgaben, etwa in Gartenarbeit oder auf Baustellen. (Johann Gräfenhain, Titus Florin)
Der Fischreiherschreck demonstriert ein KI-gestütztes Vergrämungssystem. Eine Kamera am NVIDIA AGX Orin erfasst die Umgebung, während ein auf den COCO-Klassen trainiertes Objekterkennungsnetzwerk interessante Objekte wie Menschen oder Vögel erkennt und verfolgt. Die Zielposition wird über ein ELFIN-Funkmodul per WLAN an ein AKSEN-Board auf einem LEGO-Roboter übertragen. Beim Tracking richtet sich der Roboter auf das Ziel aus und verschießt einen Tischtennisball. (Luke Bartel)




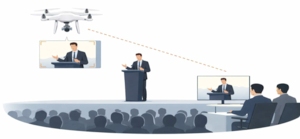 Autonomes Personenfolgesystem mit einer Drohne (Q. T. A. Nguyen, Y.
C. Camacaro Querales)
Autonomes Personenfolgesystem mit einer Drohne (Q. T. A. Nguyen, Y.
C. Camacaro Querales)
Im KI-Projekt des 5. Semesters im Wintersemester 2025/26 entwickelten Studierende im DrohnenLab intelligente Flugdemonstratoren auf Basis der Ryze Tello-Plattform. Ziel war die Umsetzung autonomer oder teilautonomer Flugverhalten durch die Kombination von Echtzeit-Bildverarbeitung, Flugsteuerung und externer Entscheidungslogik.
Die Aufgabenstellung umfasste die Entwicklung innovativer Anwendungsszenarien unter Nutzung der integrierten Kamerasysteme sowie Python-basierter Steuerungsbibliotheken – von bildverarbeitungsbasierter Objektverfolgung bis hin zu automatisierten Navigations- und Interaktionsmechanismen.
Nach einer initialen Einarbeitungsphase in die Programmierung und Steuerung der Drohnen entwickelten die drei Teams eigene Konzepte zur Realisierung intelligenter Flugfunktionen, z. B. kamerabasierter Zielverfolgung, automatisierter Landung mit Energieversorgung oder autonomer Bilddatenerfassung für Panorama- und Navigationsaufgaben.

Im Projekt wurde ein autonomer Verfolgungsmodus realisiert, bei dem eine Drohne eine erkannte Zielperson in Echtzeit verfolgt und dabei ihre Fluglage kontinuierlich anpasst. Die Videodaten der On-Board-Kamera werden an einen externen Rechner übertragen, wo ein Deep-Learning-basiertes Detektionsmodell (z. B. MobileNet-SSD) die Position der Zielperson bestimmt und daraus Steuerbefehle für Yaw-, Distanz- und Höhenregelung abgeleitet werden. Bei Verlust der Zielperson wechselt das System automatisch in einen sicheren Such- oder Hover-Modus.
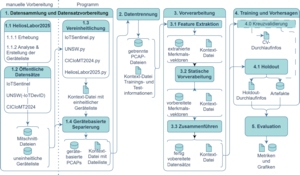
Die Masterarbeit untersucht, inwieweit eine passive paketbasierte Netzwerkverkehrsanalyse zur automatischen Klassifikation von Geräten in medizinischen IT-Infrastrukturen eingesetzt werden kann. Ziel ist die Unterstützung eines automatisierten Netzwerkinventars, das insbesondere im Krankenhausumfeld eine zentrale Rolle für IT-Sicherheit und Systemübersicht spielt.
Ausgangslage: Trotz der hohen Bedeutung aktueller Netzwerkinventare mangelt es an öffentlich verfügbarer Forschung zur automatisierten Geräteerkennung im Gesundheitswesen. In der Arbeit wird daher ein Proof of Concept zur Geräteklassifikation in medizinischen Netzwerken durch Reproduktion einer bestehenden Forschungsarbeit implementiert und evaluiert.

Datengrundlage:
Methodik: Auf Basis passiv aufgezeichneter Netzwerkpakete werden paketbasierte Merkmale extrahiert und mit überwachten Lernverfahren klassifiziert. Hierzu werden verschiedene Entscheidungsbaum- und Random-Forest-Modelle trainiert und anhand üblicher Metriken wie dem Macro-F1-Score evaluiert. Aufgrund unausgeglichener Datensätze erfolgt die Bewertung über aggregierte Vorhersagen. Bei der Evaluation muss das durch geräteweises Splitting verursachte Data Leakage beachtet werden. Ein Klassifikations-Ansatz aus [1] wird zur Analyse reproduziert.
Ergebnisse:
Fazit: Die Arbeit zeigt, dass verhaltensbasierte Geräteklassifikationsmethoden aus IoT-Netzwerken erfolgreich auf medizinische IT-Infrastrukturen übertragbar sind. Eine automatische Unterstützung bei der Inventarisierung von Krankenhausnetzwerken erscheint damit plausibel.
Kolloquium: 19.02.2026
Betreuer: Prof. Dr. Michael Pilgermann, Dipl.-Inform. Ingo Boersch
Download: A1-Poster
Lizenz: Creative Commons CC BY-NC-SA 4.0 - Namensnennung – Nicht kommerziell – Weitergabe unter gleichen Bedingungen 4.0 International

Die Masterarbeit untersucht die Leistungsfähigkeit von Large Language Models (LLMs) zur Extraktion strukturierter Rechnungsdaten aus PDF-Dokumenten. Der praktische Einsatzkontext ist die Berliner FinTech-Firma aifinyo AG, die monatlich rund 15.000 Rechnungen verarbeitet und eine robuste automatisierte Erfassung von Rechnungsnummer, -datum und -betrag benötigt.
Ausgangslage: Die bestehende OCR-Lösung (Gini) zeigt Schwächen bei variablen Rechnungslayouts. Die Arbeit prüft, ob LLM-basierte Verfahren eine signifikant robustere Alternative darstellen können.

Evaluierte Modelle und Strategien:
Evaluationsplattform: Es wurde eine webbasierte Plattform entwickelt, die Dokumente mit Ground-Truth verwaltet, Prompting-Strategien konfiguriert, automatisierte Ausführungen durchführt und sämtliche Metriken sowie Tokenverbrauch und Laufzeiten erfasst. Technische Basis: Ruby on Rails, PostgreSQL, einheitliche LLM-Service-API, Textextraktion mittels PDFPlumber und Tesseract.
Ergebnisse:
Fazit: LLM-basierte Methoden bieten eine klar überlegene Rechnungsdatenextraktion im Vergleich zur OCR-Lösung. In Kombination aus Genauigkeit, Layout-Robustheit und Stabilität stellt Claude 3 Sonnet mit Few-Shot-CoT den besten Ansatz dar. Empfohlen wird ein hybrides System (LLM-Hauptverarbeitung + OCR-Fallback). Potenzial zukünftiger Arbeiten: multimodale LLMs, Fine-Tuning und Kostenoptimierung.
Kolloquium: 03.11.2025
Betreuer: Prof. Dr. Emanuel Kitzelmann, Technische Hochschule Brandenburg; Prof. Dr. Roland Fassauer, CODE University of Applied Sciences
Download: A1-Poster, Abschlussarbeit
Lizenz: Creative Commons CC BY-NC-SA 4.0 - Namensnennung – Nicht kommerziell – Weitergabe unter gleichen Bedingungen 4.0 International

Der Fachbereich Informatik und Medien der Technischen Hochschule Brandenburg freut sich, Frau Prof. Dr.-Ing. Darya Kastsian zum 1. September als neue Professorin für Künstliche Intelligenz begrüßen zu dürfen.
Frau Prof. Kastsian bringt langjährige Erfahrung aus Forschung und Entwicklung mit. Unter anderem war sie seit 2015 in verschiedenen Funktionen bei der Siemens AG in Berlin tätig und entwickelte dabei Lösungen in Simulation, Künstlicher Intelligenz und Optimierung für den 3D-Druck.
Mit ihrer Berufung startet am Fachbereich die neue
Vertiefungsrichtung „Künstliche Intelligenz (KI)/Artificial Intelligence“
im Masterstudiengang Informatik. Den Auftakt bildet die von Prof.
Kastsian geleitete Veranstaltung „Deep Learning“.

Diese Bachelorarbeit im industriellen Kontext (Robert Bosch GmbH) untersucht, wie sich Sourcing Decisions (SD) mittels interpretierbarer Modelle automatisieren lassen – mit Möglichkeit zur menschlichen Intervention. Zum Einsatz kommen klassifikationsbasierte Entscheidungsbäume (Decision Trees, DT), deren Struktur und Vorhersagen nachvollziehbar bleiben sollen.
Vorgehen: Entsprechend des Data-Science-Workflows werden Rohdaten analysiert, bereinigt und aufbereitet (u. a. Umgang mit fehlenden/fehlerhaften Werten). Aus bestehenden Merkmalen werden neue Features abgeleitet, kategoriale Merkmale numerisch kodiert und numerische Merkmale in den Bereich −1 bis 1 skaliert. Das Zielmerkmal wird linear in fünf Klassen gebinnt, die das Modell später vorhersagt.
Train/Test-Split: Der verarbeitete Datensatz wird in Trainings- und Testmenge aufgeteilt; die Klassenverteilungen der Teilmengen entsprechen derjenigen des Gesamtdatensatzes und gelten damit als repräsentativ.
Hyperparameter-Tuning: Per Gridsearch werden verschiedene Setups
verglichen; das gini-Kriterium zeigt die besten mittleren
Genauigkeiten. Die Analyse der Genauigkeiten über der Baumtiefe weist ab
Tiefe 8 eine zunehmende Überanpassung aus, weshalb eine maximale Tiefe
von 7 als optimal gewertet wird. Domänenexperten bestätigen, dass das
resultierende Modell für „normale“ Fälle gut geeignet ist; für
Spezialfälle fehlen teils relevante Informationen oder deren Nutzung im
Modell.
Vergleich zu anderen ML-Ansätzen: Regressions-Entscheidungsbäume und Random-Forest-Modelle liefern leicht höhere Genauigkeiten; der Zugewinn rechtfertigt jedoch nicht den Verzicht auf die Einfachheit und Interpretierbarkeit der Klassifikations-DTs.
Fazit: Die Modellierung von Sourcing Decisions mit den vorliegenden Daten und ML ist grundsätzlich möglich. Das Modell meistert Standardszenarien, während besondere Fälle zusätzliche Merkmale bzw. Regeln erfordern.

Kolloquium: 09.09.2025
Betreuer: Prof. Dr. Emanuel Kitzelmann, Technische Hochschule Brandenburg; Marc-Alexander Frey, Robert Bosch GmbH
Download: A1-Poster
Creative Commons – CC BY-NC-SA – Namensnennung – Nicht kommerziell – Weitergabe unter gleichen Bedingungen 4.0 International


Robin Wagner, Masterstudent im Fachbereich Informatik und Medien an der THB, präsentierte im Juli 2025 ein Poster und long Paper auf dem Student Research Workshop der ACL 2025 in Wien. Sein Beitrag ist eine systematische Literaturübersicht zu Methoden, die sogenannte Halluzinationen in Antworten großer Sprachmodelle (LLMs) durch die Integration von Wissensgraphen während des Inferenzprozesses reduzieren.
Während einer intensiven 90-minütigen Postersession diskutierte er seine Ergebnisse mit einer Vielzahl neugieriger Forschender – darunter Industrievertreter, Studierende und Professor*innen mit Hintergrund in Knowledge Graphs und Retrieval-Augmented Generation (RAG). Die Atmosphäre war offen und herzlich; die Community zeigte sich außerordentlich zugänglich.
Robin dankt der Association for Computational Linguistics für diese Möglichkeit und seinen Betreuern Prof. Dr. Emanuel Kitzelmann und Dipl.-Inform. Ingo Boersch für ihre Unterstützung. Die Teilnahme vor Ort wurde durch die Technische Hochschule Brandenburg ermöglicht.
Das Paper ist online unter aclanthology.org/2025.acl-srw.53 abrufbar.



Bei der 6. Langen Nacht der Wirtschaft in der Kleeblattregion präsentierte sich das KI-Labor der Technischen Hochschule Brandenburg mit einem eigenen Stand im KMG-Klinikum in Kyritz. Vor Ort waren Professor Dr. Emanuel Kitzelmann sowie die Masterstudierenden Albert Zacher und Max Tepper, die Einblicke in ihr aktuelles Projekt zur Verbindung von KI und Robotik gaben.
Im Mittelpunkt stand der vierbeinige Roboter Unitree Go2 EDU, der mit dem Open-Source-Framework ROS 2 für autonome Navigation und Interaktion ausgestattet wurde. Die Besucherinnen und Besucher konnten sich vor Ort davon überzeugen, wie der Roboter seine Umgebung wahrnimmt und sich fortbewegt. Das Projekt wurde im Masterstudiengang Informatik durchgeführt und adressiert reale Anwendungsszenarien wie Rettungseinsätze und Wartungsaufgaben.
Der Stand war Teil einer Kooperation mit der Präsenzstelle Prignitz und bot Wissenschaft zum Anfassen für alle Altersgruppen.



In seiner Bachelorarbeit entwickelte Lasse Broer ein performantes KI-System zur Instanzsegmentierung auf einem Jetson AGX Orin, das Bilddaten einer Basler Hochgeschwindigkeitskamera in Echtzeit mit einem YOLO-Seg-Modell verarbeitet.
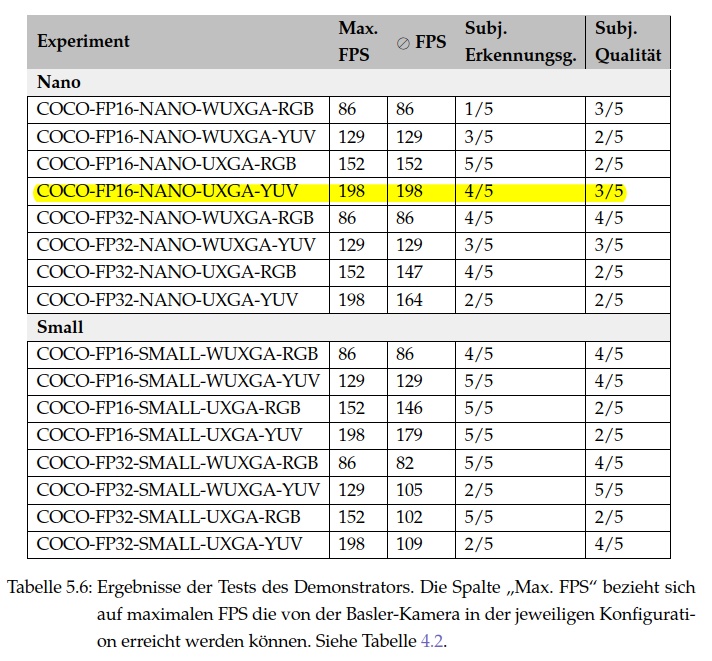
Im Mittelpunkt der Arbeit stand die vollständige Installation und Konfiguration aller Komponenten sowie die Evaluation der Bildverarbeitungspipeline hinsichtlich Genauigkeit, Geschwindigkeit und Latenz. Zur Veranschaulichung entstand ein Demonstrator auf Basis von NVIDIA DeepStream, der auf einer Rampe zwei Objekte bei bis zu 198 Hz analysiert.
Das entwickelte Testframework erlaubte die gezielte Variation zentraler Parameter (Präzision, Auflösung, Modellvariante, Farbformat) zur Bewertung ihrer Auswirkungen auf die Gesamtperformance. In 16 Experimenten wurden objektive Messwerte (z. B. Latenz) und subjektive Kriterien (Segmentierungsqualität) erfasst.
Die Ergebnisse zeigen, dass eine robuste Instanzsegmentierung auf Edge-Hardware mit sorgfältiger Abstimmung möglich ist – auch bei extremen Anforderungen an Echtzeitfähigkeit und Geschwindigkeit.

Kolloquium: 31.03.2025
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr. Emanuel Kitzelmann
Download: A1-Poster

Im Rahmen seines Masterprojekts im WS24/25 entwickelte Arne Allwardt einen autonomen mobilen Roboter auf Basis des TurtleBot3 mit einem OpenManipulator-X-Arm. Ziel des Projekts war es, einen Prototypen zu realisieren, der selbstständig bestimmte Objekte an definierten Lagerplätzen aufsucht, greift und zurückbringt.
Der Roboter kartiert mit Hilfe der SLAM Toolbox seine Umgebung, lokalisiert sich über AMCL (Adaptive Monte Carlo Localization) und steuert mit Nav2 gezielt Positionen an, an denen blaue oder rote Bälle liegen. Mit Hilfe von OpenCV erkennt das System die blauen Bälle und nutzt den Manipulator, um sie zu greifen. Rote Bälle werden ignoriert.
Der Pfad zum Ziel wird über die navigate_to_pose-Action
generiert, wobei Costmaps aus Laserdaten entstehen. Für die
Interaktion von Bewegung, Wahrnehmung und Greifoperationen wurde ein MultiThreadedExecutor
verwendet. Die Steuerung basiert auf einem Zustandsautomaten, der
mit der Python-Bibliothek transitions umgesetzt wurde.
Für die Objekterkennung wurde eine Hue-basierte Farberkennung mit Erosion eingesetzt. Die größte erkannte Kontur wird als Ziel angenommen. Der Greifvorgang erfolgt blind, basierend auf Segmentierung und Kameraanalyse.

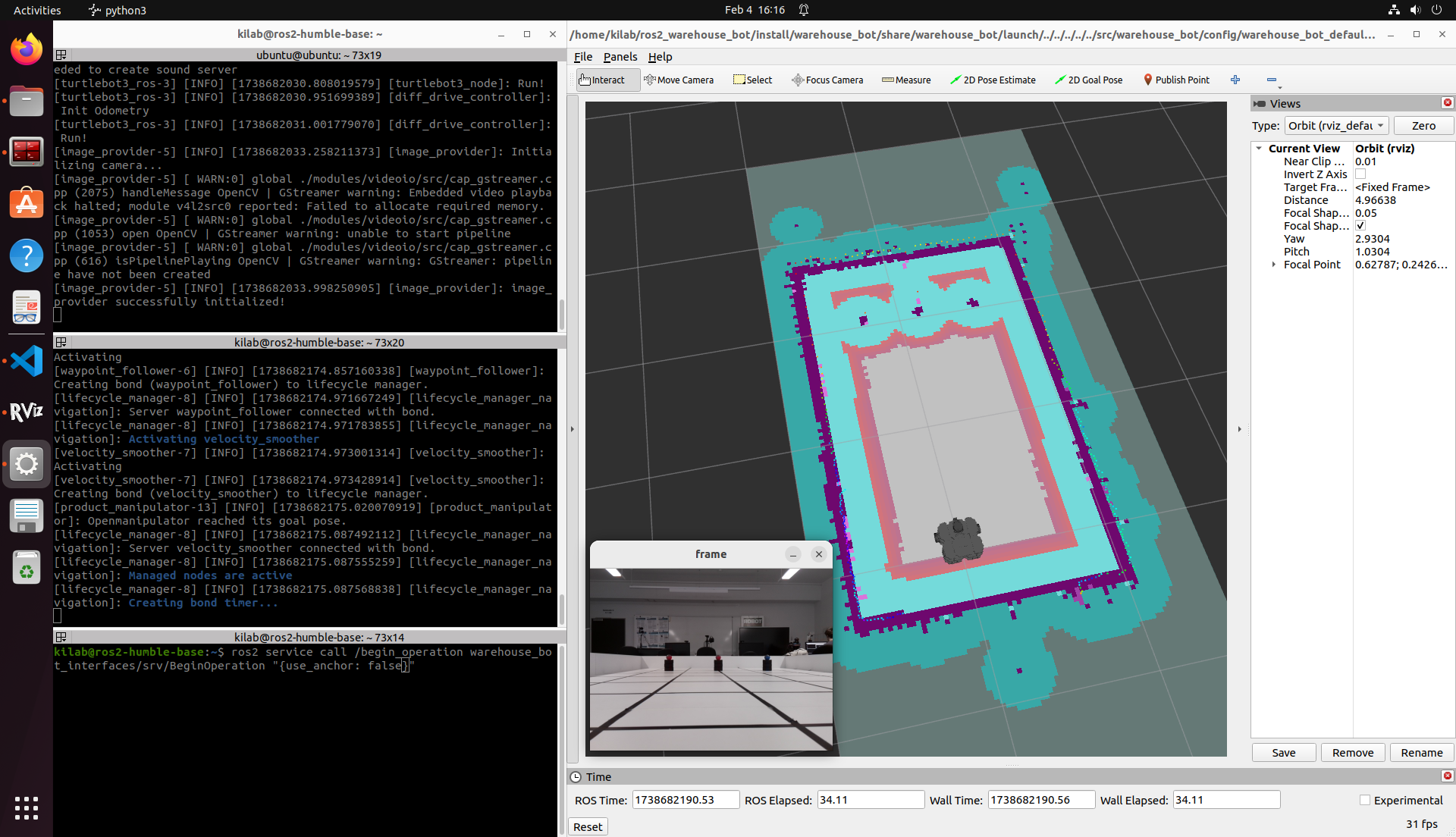
Die Navigations- und Greifvorgänge wurden in umfangreichen Szenarien getestet. Die Robustheit hängt von Faktoren wie Startposition und Beleuchtung ab – die automatische Lokalisierung konnte aber viele Störungen kompensieren. Das Video zeigt einen typischen Durchlauf.
Im Projekt Künstliche Intelligenz des Wintersemesters 2024/25 entwickelten Studierende in 2- bis 3-köpfigen Teams kreative Robotiklösungen, bei denen autonome und intelligente Handlungen im Vordergrund standen. Ziel war es, Demonstratoren zu realisieren, die nicht nur technisch funktionieren, sondern auch einen Showcase-Charakter haben.
Ausgangspunkt war eine Auswahl verschiedener Robotersysteme: Turtlebots, NAOs, AKSEN-Boards, OpenManipulator-X und das leistungsstarke NVIDIA AGX Orin. Nach einer dreiwöchigen Konzeptionsphase mit intensiven Technik-Demos, individueller Betreuung und Feedback entwickelten die Teams eine eigene Projektvision mit intelligentem Verhalten – z. B. Navigation, Sprachausgabe, Objekterkennung, Planung oder Lernen.
In mehreren Zwischenetappen wurden die Prototypen realisiert, getestet und in einer Generalprobe verteidigt. Die Live-Vorführung am 15. Januar 2025, dem Tag der offenen Projekte der Bachelorstudierenden des 5. Semesters, verlief anschaulich und erfolgreich. Gezeigt wurde eine breite Palette an Anwendungen – von (physisch) mobilen Assistenten über interaktive Lernsysteme bis hin zu Echtzeit-KI auf ressourcenarmer Hardware.
Der Sortierroboter zeigt, wie mit minimaler Hardware autonome Navigation und Farbsortierung für logistische Anwendungen realisiert werden kann. Der Roboter fährt auf der Suche nach Objekten ins Lager und bringt Fundstücke je nach Farbe zu definierten Abholpunkten. Die Planung erfolgt per Breitensuche auf einem speicherschwachen AKSEN-Board (7 KB) – eine technische Herausforderung mit großem Potenzial z. B. für die Eingangssortierung in einem Warenlager.
Findus kombiniert Pfadplanung mit Sprachrückmeldung: Der Roboter durchsucht Räume nach verlegten Gegenständen und meldet sie über den NAO-Roboter per Sprache – ein Konzept für Menschen mit eingeschränktem Sehvermögen.
Der Dungeonmaster NAO verwandelt den Roboter in einen interaktiven Spielleiter, der Würfel erkennt und mit Nutzer*innen eine Geschichte durchlebt. Die Spiellogik ist als Automat (Abb. oben) realisiert und deklarativ in einer Excel-Tabelle hinterlegt – ein innovativer Ansatz für Lernspiele mit humanoiden Robotern.
Die Gruppe Drohnenparkour trainierte mit Teachable Machine ein neuronales Netz zur Erkennung visueller Kommandos (z. B. Richtungspfeile), die während des Flugs erkannt und ausgeführt werden. Bei Erkennungsproblemen sorgt ein Spiral-Suchmuster für robuste Ausführung. Die Anwendungsvision: intuitive Drohnensteuerung mit Symbolen statt Programmierung oder Fernbedienung – ideal für Navigation in Innenräumen oder bei Suchszenarien.





An zwei Workshoptagen, dem 06.11. und 27.11.2024, nahmen neun Mitarbeitende der ZF Getriebe Brandenburg GmbH an einer Weiterbildung zur Daten-Analyse und -Modellierung mit KNIME an der Technischen Hochschule Brandenburg teil.
In vier aufeinander aufbauenden Modulen wurden zentrale Kompetenzen zur datenbasierten Entscheidungsunterstützung vermittelt. Modul 1 bot einen Überblick über die KNIME-Oberfläche, Workflows und Best Practices. In Modul 2 stand ein konkreter Anwendungsfall aus dem Vertrieb im Zentrum, bei dem es um die Automatisierung datengetriebener Berichte ging.
Modul 3 widmete sich der Modellierung und Evaluation: Themen wie Klassifikation, einfache Metriken, Entscheidungsbäume und neuronale Netze wurden ebenso behandelt wie Deployment-Prozesse. Den Abschluss bildete ein viertes Modul mit praktischer Umsetzung der erlernten Methoden in kleinen Teams.
Die Kombination aus theoretischem Input und praxisorientierter Anwendung
kam bei den Teilnehmenden sehr gut an. Der Workshop wurde von Prof.
Dr. Georg Merz, Prof. Dr. Emanuel Kitzelmann und Ingo
Boersch durchgeführt.

Die Masterarbeit entwickelt und evaluiert ein RAG-System (Retrieval-Augmented Generation) zur teilweisen Automatisierung des Kundensupports für ein Praxisverwaltungssystem (PVS) in einem realen Unternehmen.
Die Arbeit stellt die theoretischen Grundlagen von RAG vor und nutzt diese in der Konzeptionsphase zur Variantendiskussion. Die besondere Herausforderung liegt in der Komplexität der eingesetzten Technologien und der Einbettung des Systems in den realen Anwendungskontext des Unternehmens.
Die praktische Umsetzung erfolgt durch die Entwicklung eines Chatbots mit einer REST-API in TypeScript und einer GUI in JavaScript. Die Datenbasis für den Vectorstore wird automatisch aus Confluence extrahiert und aufbereitet. Der Evaluator ist in Python implementiert. Die Evaluation des Systems erfolgt zum einen über das LangSmith Framework, das die Performance anhand verschiedener Kriterien wie Latenz, Konsistenz, Prägnanz und Relevanz der Antworten misst, und zum anderen über eine manuelle Bewertung der Antworten durch Fachexperten. Insgesamt bestätigen die Tests, dass der Chatbot die Effizienz und Qualität des Kundensupports steigern kann.

Kolloqium: 29.07.2024
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr. Georg Merz
Download: A1-Poster

Ingenieure und Informatiker der „ZF Getriebe Brandenburg GmbH“ nahmen am 24.04.24 und 15.05.24 an einem Workshop im Informatikzentrum der Technischen Hochschule Brandenburg teil, bei dem sie sich gemeinsam mit Prof. Dr. Georg Merz, Prof. Dr. Emanuel Kitzelmann und Ingo Boersch intensiv dem Thema „Künstliche Intelligenz“ widmeten. Ziel der Veranstaltung war es, durch die Diskussion praktischer Anwendungsfälle, die Klärung zentraler Begriffe und praktische Hands-on-Erfahrungen ein fundiertes Verständnis von KI und Data Science zu fördern.
In den Modulen wurden verschiedene anwendungsnahe Aspekte von KI und
Data Science behandelt. Ein besonderer Schwerpunkt lag auf dem letzten
Modul, das sich mit „Use Cases und praktischer Umsetzung“ befasste. Die
erfolgreiche Teilnahme wurde durch Zertifikate bestätigt. Das Feedback
der Teilnehmenden war durchweg positiv und alle waren sich einig, die
Workshopreihe und die Zusammenarbeit fortzusetzen.

Am 01.03.2024 nahmen Prof. Kitzelmann, Prof. Pohl und Ingo Boersch für die Technische Hochschule Brandenburg am Netzwerktreffen "Roboter im Bildungskontext" an der TU Berlin teil. Ziel des Treffens war es, den Austausch über den Einsatz von Robotiksystemen als Lehrmittel zu fördern – etwa zur Vermittlung von KI-Methoden in Studium und Schule.
Die THB setzt Roboter bereits aktiv in der Lehre ein, unter anderem zur Vermittlung praxisnaher Kompetenzen im Bereich Künstliche Intelligenz. Das Netzwerk bietet dafür eine wertvolle Plattform, um Ideen, Projekte und didaktische Konzepte zu teilen. Neben der THB waren auch Vertreterinnen und Vertreter der Universität Potsdam, der Berliner Hochschule für Technik, der HU Berlin, der HTW Berlin und der Universität Paderborn beteiligt.
Besonders beeindruckend war die Präsentation von Georges A. K.
Bonga (BHT), der ein tutorielles Dialogsystem mit dem sozialen
Roboter Furhat vorstellte. Das System kombiniert GPT‑3.5-basierte
Frage-Antwort-Funktionalität mit Emotionserkennung (DeepFace) und
adaptivem Verhalten. Es wird im Rahmen seiner Masterarbeit mit dem Titel "AURALE:
Ein tutorielles System für die automatisierte Erstellung adaptiver
Lerninhalte" entwickelt. Die Arbeit wird betreut von Prof. Dr.
Martin Christof Kindsmüller (THB) und Prof. Dr. Ilona Buchem (BHT).

Im Rahmen des Masterprojektes "Künstliche Intelligenz - ChatGPT in Action" im WS23/24 wurde ein Prototyp einer Robotersteuerung entwickelt. Ziel des Projektes ist die Entwicklung und Evaluierung eines Systems zur Steuerung eines Pflegeroboters durch Kommunikation mit einem Large Language Model (LLM) am Beispiel eines rudimentären Bringeroboters. Es geht um die Untersuchung der Eignung des LLM als Schnittstelle zwischen einem Roboter und einer körperlich eingeschränkten Person, um einfache Aufgaben in der Sichtweite und unter Kontrolle des Nutzers zu übernehmen.
Die Methode zur Entwicklung des Systems umfasst den Entwurf und die Implementierung einer Testarchitektur, die aus zwei Hauptkomponenten besteht: LLM-Access zur Verwaltung der Kommunikation und RobotAPI Node zur Schnittstelle mit dem Roboter. Die Architektur basiert auf der Verwendung von ROS 2 Humble und beinhaltet ein effizientes Kontextmanagement und die Speicherung von Konversationen. Der Kommunikationsfluss beginnt mit dem Startprompt des LLM und kann iterativ zwischen Benutzeranfragen und Funktionsergebnissen wechseln.
In Praxistests wurde die Benutzbarkeit des Systems anhand eines Hindernisparcours getestet, bei dem ein simulierter turtlebot mit Laserscanner in einem slalom durch Sprachkommandos geführt wurde. Die Wege und Verzögerungen wurden aufgezeichnet.
Die Ergebnisse der Tests zeigen, dass GPT-3.5 als Schnittstelle für die Steuerung von Robotern nur bedingt geeignet ist. Positiv hervorzuheben sind die flexible Verwendung von Funktionsaufrufen und die Fähigkeit, komplexes Verhalten zu erklären. Negativ sind jedoch die hohen Verzögerungen und Missverständnisse. Die Auswertung der Praxistests ergab eine durchschnittliche Reaktionszeit von 2,3 bis 2,4 Sekunden mit Schwankungen zwischen den Durchläufen. Zur Verbesserung des Systems wird die Verwendung von Modellen mit geringerer Verzögerung und sicherheitsrelevanten Sperren empfohlen. Insgesamt zeigt das Projekt das Potenzial und die Grenzen von LLMs als Schnittstelle für die Robotersteuerung im Pflegebereich auf.
Vortrag: 08.02.2024
Betreuer: Dipl.-Inform. Ingo Boersch


Im Rahmen des Masterprojekts "Künstliche Intelligenz - ChatGPT in AKtion" im WS23/24 wurde von drei Erasmus-Studierenden ein Prototyp für einen Email-Checker entwickelt, der mit Hilfe eines Sprachmodells eine Email in Zimbra mit einem Chrome-Plugin auf Anzeichen von Phishing überprüft
Das Prinzip besteht darin, dass der Emailtext mit einem speziell entwickelten Prompt, der teilweise durch einen genetischen Algorithmus optimiert wurde, mit GPT-3.5 klassifiziert wird. Dabei berücksichtigt GPT bestimmte psychologische Aspekte [SMG22] und kann bei Bedarf auch erklären, warum die Email als Phishing erkannt wurde. Die Erkennungsrate auf einem Datensatz von Kaggle [Cha23] ist relativ hoch, fast 90% der Testmails werden korrekt als "Safe Email" oder "Phishing Email" klassifiziert. Das beste Modell hatte eine FP-Rate von knapp 7%. Das System soll Emails nicht aussortieren, sondern nur einen Warnhinweis in Form einer Ampel einblenden.
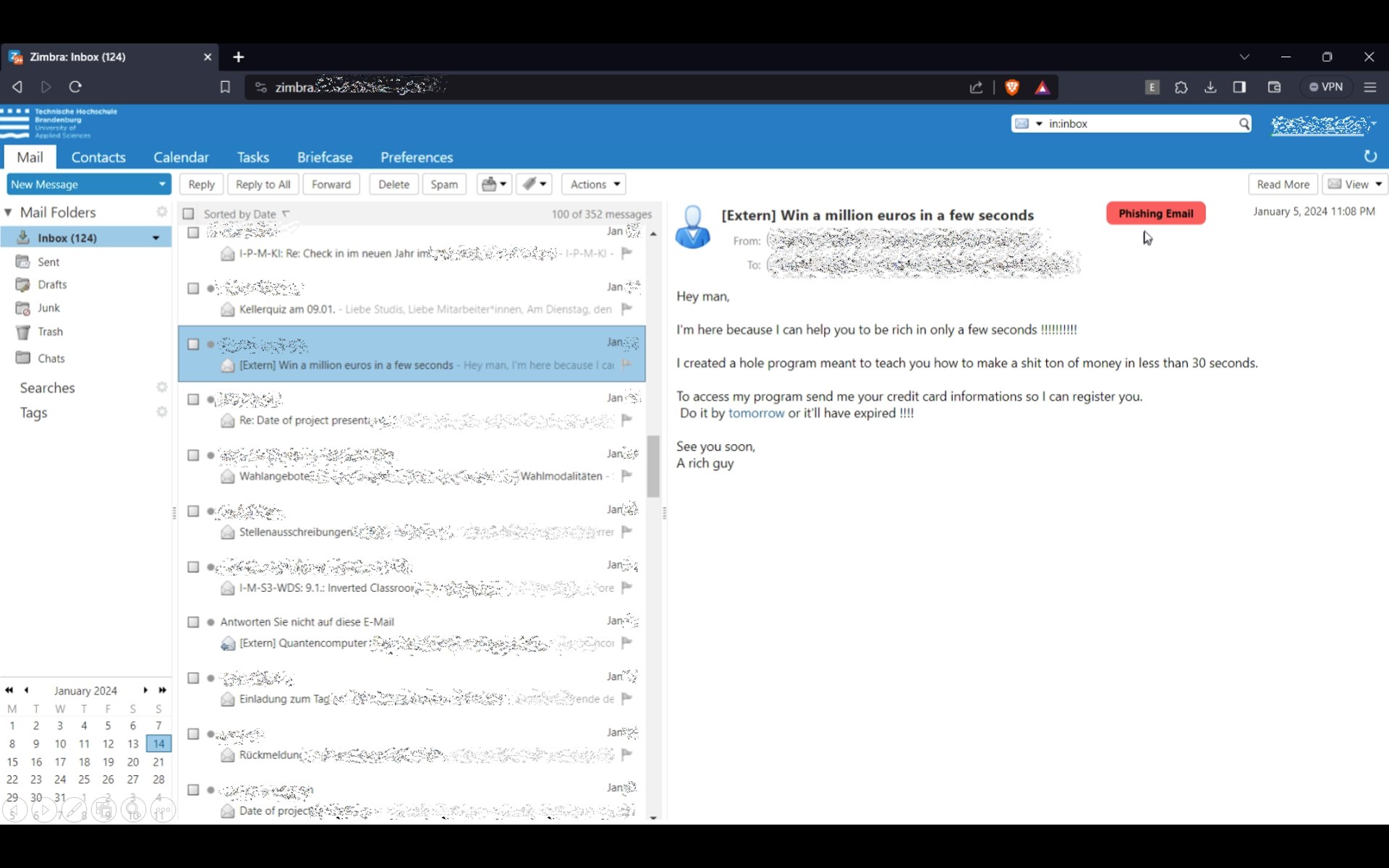

Diese Forschung trägt zum Verständnis bei, wie LLMs Cybersicherheits-Tools zum Erfolg verhelfen können. Die Bilder zeigen eine Phishing-Email und die Reaktion auf diese Email mit einer Ampel und einer Erklärung. Die Erklärung erläutert in einfachen Worten, welche Anzeichen von Phishing diese Email aufweist.
[Cha23] Chakraborty, Subhadeep: Phishing Email Detection. http://dx.doi.org/10.34740/KAGGLE/DSV/6090437. Version: 2023. https://www.kaggle.com/datasets/subhajournal/phishingemails/data
[SMG22] Shahriar, Sadat ; Mukherjee, Arjun ; Gnawali, Omprakash: Improving Phishing Detection Via Psychological Trait Scoring. 2022
Vortrag: 15.01.2024
Betreuer: Prof. Dr. Georg Merz, Dipl.-Inform. Ingo Boersch
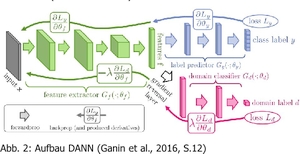
Die Arbeit im realen industriellen Kontext konzentriert sich auf die Implementierung des Domain-Adversarial Trainings neuronaler Netze (DANN) zur Überbrückung einer Domänenlücke zwischen verschiedenen Kameratypen, speziell Industriekameras und Smartphone-Kameras. Ziel der Arbeit ist es, ein Regressionsmodell zu trainieren und dieses gegen einen anderen Ansatz zu evaluieren, der Contrastive Learning for Unpaired Image-to-Image Translation (CUT) verwendet.
Die Trainingsdaten bestehen aus vorverarbeiteten Bildern von Laserschnittkanten. Um die Untersuchungen möglichst praxisnah zu gestalten, wird die Anzahl der verwendeten gelabelten und ungelabelten Bilder begrenzt. Durch die Anwendung von 3-way-holdout und einer Hyperparameter-Suche wird ein optimiertes DANN-Modell ausgewählt.
In den Ergebnissen zeigt sich, dass DANN in der Zieldomäne bessere Ergebnisse erzielt als bisherige Regressionsmodelle, jedoch die Domänenlücke nicht vollständig schließt. Bei einem Vergleich mit CUT stellt sich heraus, dass beide Ansätze ihre eigenen Vor- und Nachteile haben, sodass keine eindeutige Empfehlung ausgesprochen werden kann.

Kolloqium: 04.10.2023
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Jochen Heinsohn, Aastha Aastha, TRUMPF SE + Co. KG
Download: A1-Poster
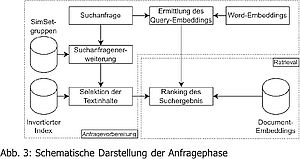
Die Arbeit konzentriert sich auf die Evaluation eines Word-Embedding-basierten Information-Retrieval-Systems, das von der Fraunhofer-Gesellschaft zum Patent angemeldet wurde. Ein besonderes Merkmal des IR-Systems ist die Verwendung von "SimSets" als zentrale Datenstruktur, die dazu dient, die Zeit für die Ermittlung der Suchergebnisse zu minimieren. Die Arbeit vergleicht dieses System mit einer Volltextsuche und einer durch einen domänenspezifischen Thesaurus erweiterten Volltextsuche, um deren Effektivität zu bewerten.
In der Arbeit werden drei verschiedene Evaluationsmethoden vorgestellt: Online-Evaluation, Interactive-Evaluation und die Testdatensatz-basierte Evaluation, die dann für die Untersuchung verwendet wird.
Die Ergebnisse zeigen, dass das Word-Embedding-basierte IR-System durch die Verwendung von SimSets in der Lage ist, zusätzliche Textinhalte im Vergleich zu einer herkömmlichen Volltextsuche zu ermitteln. Zudem ist die Effektivität des Systems bei einer domänenspezifischen Textsammlung vergleichbar mit einer Volltextsuche, die durch einen domänenspezifischen Thesaurus erweitert wird.

Kolloqium: 19.06.2023
Betreuer: Prof. Dr.-Ing. Jochen Heinsohn, Prof. Dr. rer. nat. Thomas Hoppe (Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V.)
Download: A1-Poster

Ein akustikbasiertes Prüfsystem für Steckverbindungen soll auf akustische Einflussfaktoren untersucht werden, um es prozessfähig zu integrieren. In der Vergangenheit wurden einzelne Aspekte der Realumgebung durch Feldtests betrachtet, um das System abzusichern. Ziel dieser Arbeit ist es, eine systematische Teststrategie zur Simulation von Störfaktoren auf das KI-System zu entwickeln, anzuwenden und eine Analyse basierend auf berechneten Ergebnissen durchzuführen, um das Bewertungsverhalten des Systems zu ermitteln und vorhersehbar zu machen.
Die systematische Teststrategie beinhaltet die Modifikation von Eingabedaten für das KI-System und die Erfassung von Veränderungen im Bewertungsverhalten. Für die Modifikation werden Techniken der Signalverarbeitung angewandt, um Varianz in den Daten und Einflussfaktoren auf das System zu simulieren. Techniken wie Frequenzfilterung, Tonverschiebung und Interferenz von Stör- und zu bewertenden Geräuschen sind integraler Bestandteil der Modifikationskette. Nachdem eine modifizierte Aufnahme erzeugt wurde, erfolgt eine Bewertung durch das KI-System, welches eine Liste binärer Klassifikationen und zugehörige Konfidenzwerte ausgibt. Zur Generierung analysierbarer Bewertungen wurde ein spezieller Datensatz erstellt, der aus Aufnahmen von Steckverbindungen eines bestimmten Steckertyps und verschiedenen Störgeräuschen besteht.
Die Analyse führte zu einer Rangliste der Störfaktoren, zu den für die KI-Bewertung relevanten Frequenzbereichen und zur Reaktion des Systems auf die Tonverschiebung. Die stärksten Einflussfaktoren waren das Rascheln mit ISO-Clips und einmaliges Händeklatschen. Die wichtigsten Frequenzbereiche für die Bewertung der KI lagen zwischen 4410 bis 6615 und 15434 bis 17640 Hz. Die Reaktion des Systems auf die Tonverschiebung zeigte einen Abfall der Konfidenz, wobei der Abfall bei einer Verschiebung in den hochfrequenten Bereich stärker war. Durch die Analyse konnten Funktionen erstellt werden, die die Reaktion der KI auf verschiedene Einflüsse beschreiben, und somit konnte das Erreichen von Bewertungsgrenzen vorhergesagt werden.
Kolloqium: 26.01.2023
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Jochen Heinsohn, Philipp Stephan (M.Sc.), Dipl.-Ing. (FH) Marcel Preibisch (Mercedes-Benz AG)
Download: A1-Poster

Die Aufgabe besteht darin, einen systematischen Review über die Erkennung von Gebärdensprachen durchzuführen, um einen Überblick über die vorhandenen Gebärdensprachenerkennungstechnologien zu geben. Die Forschungsfrage lautet: "Welche Anwendungen mit welchen Bedingungen weisen die visuellen Gebärdensprachenerkennungen auf?" Die Arbeit konzentriert sich auf Technologien, die Kameras verwenden, um Gebärden zu erfassen, und zielt darauf ab, praktisch umsetzbare Anwendungen herauszuarbeiten und deren Umsetzungsvoraussetzungen zu definieren.
Die Literatur wird mithilfe von Suchmaschinen und dem booleschen Suchverfahren gesucht. Die Auswahl der Literatur erfolgt anhand von festgelegten Ein-, Ausschluss- und Qualitätskriterien. Die Einschlusskriterien beinhalten, dass die Literatur im Jahr 2022 veröffentlicht wurde, auf Deutsch oder Englisch verfasst ist, aus dem Informatikbereich stammt und dynamische visuelle Eingaben der Technologien beinhaltet. Das Ausschlusskriterium exkludiert das Erkennen von Gesten, die nicht zu einer Gebärdensprache gehören. Die Qualitätskriterien bewerten, wie akkurat eine Quelle ihre Ergebnisse darstellt. Die ausgewählten Artikel werden nach Qualitätspunkten sortiert und diejenigen mit einer Punktzahl von über vier werden für den Review verwendet.
Die ausgewählten Literaturen stellen Technologien vor, die zwischen sechs und 1295 Klassen erkennen können und Sprachen wie Englisch, Chinesisch, Argentinisch, Deutsch und Indonesisch erkennen können. Die Erkennung geschieht entweder zu isolierten Wörtern oder zusammenhängenden Gebärden. Es fehlen jedoch oft Angaben, die wichtig zur Bestimmung der Anwendbarkeit sind, wie zum Beispiel die benötigte Rechenleistung. Mit bestimmten Annahmen könnten fünf der Technologien in Bereichen wie Infopunkten oder Apps einsetzbar sein. Es wird festgestellt, dass die Quellen keine deutlichen Anwendungen für die vorhandenen Gebärdensprachenerkennungen definieren, aber mit guter Qualität der Quelle lassen sich Schlüsse auf mögliche Einsatzfelder der Technologien ziehen.
Kolloqium: 07.10.2022
Betreuer: Prof. Dr. Rolf Socher, Dipl.-Inform. Ingo Boersch
Download: A1-Poster

Ziel der Arbeit ist die Entwicklung eines künstlichen Bewegungsapparates für virtuelle Kreaturen (sog. „Swimbots“), welches aufbauend auf dem KipEvo-Projekt in einer in Unreal Engine implementierten Simulationsumgebung der Evolution unterzogen werden. Die Wirksamkeit der Swimbots wird durch Experimentdurchläufe untersucht und diskutiert.
Konzept
Die Swimbots werden als Mehrkörpersystem mit mehreren kinematischen Ketten modelliert. Die Drehmomente der Gelenke werden durch ein neuronales Netz berechnet, das auf vielfältige Eingangsreize aus externen und Propriozeptoren reagiert. Die ausgabe der Drehmomente erfolgt in die Physik-simulation der Enreal Engine. Sowohl die Körperbeschreibung (Baum) als auch die Wichtungen des neuronalen Netzes werden in der Evolution durch genetische Operatoren 8Mutation) verändert, so dass neuartige Individuen entstheen, die ebenfalls am Wettstreit um Futter teilnehmen.
Jede virtuelle Kreatur wird aus einem Genotyp gebildet, in welchem Basiseigenschaften (wie z.B. die Sichtfähigkeit oder Reproduktionseigenschaften), die Körperstruktur und genexpressive Eigenschaften in Form einer JSON-Struktur gespeichert sind. Diese bilden die Grundlage für die Verhaltensweise, sowie den Körperbau der Individuen ab. Eine erfolgreiche Evolution der Swimbots hängt von der Zusammensetzung dieser Eigenschaften sowie der sich daraus bildenden Anpassungsfähigkeit ab. Durch asexuelle Reproduktion sind die Swimbots in der Lage Nachkommen zu erzeugen. Dies wird durch die Aufnahme von Energie erreicht, welche die Swimbots in Form von Nahrungsobjekten in der Simulationswelt aufsammeln können. Eine geeignete Bewegungsmechanik, durch welche eine Fortbewegung zur Nahrung ermöglicht wird, sorgt für das Überleben der Kreatur.
Durch das integrierte Ökosystem können Eigenschaften beeinflusst werden, wodurch sich der Evolutionsverlauf der Swimbots verändern kann. Die simulation kann unter Beibehaltung der Physikmodellierung bis zu 10fach beschleunigt werden.

Kolloqium: 13.09.2022
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. habil. Michael Syrjakow
Download: A1-Poster, Abschlussarbeit
Im Rahmen dieser Bachelorarbeit wird der Greifarm OpenManipulator-X der Firma ROBOTIS in Betrieb genommen. Der OpenMANIPULATOR-X ist ein Greifarm der Firma ROBOTIS, der mit dem Robot Operating System 2 (ROS2) betrieben wird. Für diese Arbeit wird er auf einer stationären Basisplatte montiert. Alternativ besteht die Möglichkeit ihn auf dem mobilen Roboter TurtleBot3 WafflePi zu montieren.
Es werden ein Überblick über die grundsätzlichen Vorgänge und Prozesse bei dessen Nutzung gegeben sowie die Möglichkeiten der Steuerung erprobt. Weiterhin wird die Steuerung mittels Handlungsplanung ermöglicht. Hierzu ist der Stand der Forschung auf dem Gebiet der automatischen Handlungsplanung dargestellt. Als geeignetes Planungsverfahren wird "Partial Order Planning Forward" implementiert und einem selbstgewählten Szenario (Blöckewelt) praktisch demonstriert.

Kolloqium: 24.02.2022
Betreuer: Prof. Dr.-Ing. Jochen Heinsohn, Dipl.-Inform. Ingo Boersch
Download: A1-Poster, Abschlussarbeit

Generative Adversarial Networks (GANs) sind ein aktueller Ansatz im Bereich der Deep Neural Networks. Diese Netzwerke sind in der Lage anhand von hochdimensionalen Trainingsdaten (speziell Bildern) die Verteilung der Daten zu erlernen und erfolgreich Generatoren für diese Verteilung hervorzubringen. Das Ziel dieser Arbeit besteht in der Auswahl, Implementierung und Evaluation moderner GANs zur Synthese von Bildern menschlicher Gesichter. Die besondere Schwierigkeit besteht in der Erschließung und Komplexität der theoretischen Grundlagen, einer korrekten Implementierung und insbesondere in der Auswahl und Umsetzung geeigneter Evaluationsverfahrens zur Beurteilung der Güte der Generatoren.
Im Rahmen der Arbeit wurden drei bekannte GAN-Modelle SGAN, DCGAN, und WGAN-GP implementiert. Die Implementierung erfolgte in der Programmiersprache Python mit PyTorch. Zur Visualisierung der Ausgabe-Daten und der Ergebnisse wurde TensorBoard verwendet. Das Training der GAN-Modelle wurde auf einer NVIDIA Titan RTX Grafikkarte mit CUDA 11.1 durchgeführt.
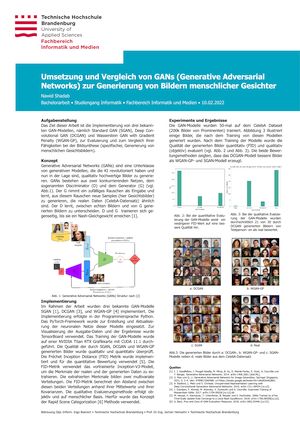
Die Qualität der durch SGAN, DCGAN und WGAN-GP generierten Bilder wurde qualitativ und quantitativ überprüft. Die Fréchet Inception Distance (FID) Metrik wurde implementiert und für die quantitative Bewertung verwendet. Die qualitative Evaluierungsmethode erfolgt objektiv und auf menschlicher Basis. Hierfür wurde das Konzept der Rapid Scene Categorization-Methode verwendet. Beide Bewertungsmethoden zeigten, dass das DCGAN-Modell bessere Bilder als WGAN-GP- und SGAN-Modell erzeugt.
Kolloqium: 10.02.2022
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Jochen Heinsohn
Download: A1-Poster,, Abschlussarbeit
Das Ziel dieser Bachelorarbeit liegt in der Gegenüberstellung von mindestens zwei Frameworks zum Management von Data Science-Experimenten. Hierbei ist der Bedarf, die Szenarien, die Einsatzbereiche und funktionalen Angebote derartiger Frameworks theoretisch zu erarbeiten und an einem konkreten Beispiel (mindestens Klassifikation mit Hyperparameteroptimierung) mit Blick auf die Nutzung in einem KMU zu evaluieren.
Eine wichtige nichtfunktionale Anforderung ist die Verständlichkeit, Nachvollziehbarkeit und Wiederholbarkeit der Arbeit.
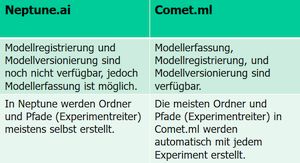
In der Arbeit werden die Frameworks Neptune.ai und Comet.ml gegenübergestellt. Nach den theoretischen Grundlagen zu MLP, CNN und Experimentverwaltung, werden die beide Frameworks anhand von ausgewählten Kriterien verglichen.
Im praktischen Teil der Bachelorarbeit werden Experimente zur Bildklassifizierung mit dem MNIST-Datensatz mit MLP und CNN in beiden Frameworks durchgeführt und verglichen. Die Unterschiede der beiden Frameworks werden in den Experimenten anhand bestimmter Kriterien wie Versionskontrolle, Abhängigkeitsmanagement, Datenversionierung, Modellversionierung, Modellregistrierung, Artefakten laden und Proto kollierung von Metadaten untersucht.

Kolloqium: 07.02.2022
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Jochen Heinsohn
Download: A1-Poster

Ziel der Arbeit sind Deep Learning-Methoden aus dem Stand der Forschung und ihre Implementierungen zur Detektion von Kanus und Ruderbooten in Zeilenkamera-Bildern. Hierzu sollen geeignete Ansätze identifiziert, exemplarisch auf dem Deep Learning-Server des Fachbereiches mit den Kanudaten trainiert, evaluiert und mit den im Einsatz befindlichen Netzversionen verglichen werden. Eine Detektion auf der Zielplattform Jetson Nano ist optional, sollte aber berücksichtigt werden.
Schwerpunkte sind die Darstellung der Funktionsweise eines sinnvoll gewählten Modells, des Vorgehens beim Training, bei der Hyperparameteroptimierung und beim Vergleich mit den Vorgängermodellen. Eine wichtige nichtfunktionale Anforderung aus Sicht des Unternehmens ist die Verständlichkeit, Nachvollziehbarkeit und Wiederholbarkeit der Arbeit.

Kolloqium: 18.02.2022
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Jochen Heinsohn, Dipl.-Inform. (FH) Daniel Schulz (IMAS Startanlagen und Maschinenbau)
Download: A1-Poster

Ziel der Arbeit ist die Untersuchung von Methoden des maschinellen Lernens zur Prognose von Qualitätsmaßen bei der Produktion von Spritzgussteilen. Die Arbeit ist eine erste Arbeit in diesem Kontext im Unternehmen und übernimmt somit eine Pilotfunktion. Das umfasst den kompletten Data Mining-Prozess von der Datenerfassung, -bereinigung, -aggregation, -vorverarbeitung und -exploration, der Definition geeigneter Gütemaße, Entwicklung eines Evaluationskonzeptes, über das Erstellen, Bewerten und Optimieren von Modellen, bis hin zur Modellselektion und nachhaltigen Dokumentation. Schwerpunkt ist das exemplarische Absolvieren aller notwendigen Schritte bis zu einem Modellvorschlag mit prognostizierter Güte.
Hierzu sind geeignete Anforderungen zu formulieren und ein sinnvoller Evaluationsprozess umzusetzen, der die erwartete Leistung der Regressoren bestimmt. Eine wichtige nichtfunktionale Anforderung aus Sicht des Unternehmens ist die Verständlichkeit, Nachvollziehbarkeit und Wiederholbarkeit der Arbeit.

Kolloqium: 28.10.2021
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr. Jochen Heinsohn, Dipl.-Ing. Stefan Lehmann (Kunststoff-Zentrum in Leipzig gGmbH)
Download: A1-Poster, Abschlussarbeit
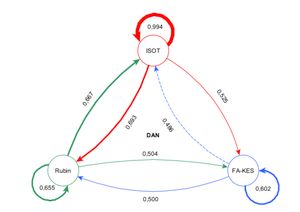
Ziel dieser Arbeit war die Untersuchung von Methoden des maschinellen Lernens für die Klassifizierung bzw. Distinktion von Fake News und echten Nachrichtenmeldungen. Einen besonderen Aspekt nimmt dabei der Faktor Transparenz ein. Untersucht wurden drei tiefe neuronale Netze und ein Modell basierend auf der logistischen Regression, sowie die Generierung von Erklärungen post-hoc mittels LIME. Die Untersuchungen wurden für drei verschiedene Datensätze vorgenommen.
Die Ergebnisse zeigen, dass die Genauigkeit der Modelle stark von dem zugrundeliegenden Datensatz abhängt. Mittels LIME konnten Erklärungen dafür gefunden werden. So finden sich in einem Datensatz Wörter, die immer in der Klasse „echte Nachrichtenmeldung“ zu finden sind. Die Modelle haben gelernt, dass es diesen Zusammenhang gibt und die Artikel anhand dieser Eigenschaften sortiert. Folglich konnten dadurch keine robusten Eigenschaften zur Unterscheidung der Klassen gelernt werden.

Kolloqium: 02.08.2021
Gutachter: Prof. Dr. Sven Buchholz, Dipl.-Inform. Ingo Boersch
Download: A1-Poster
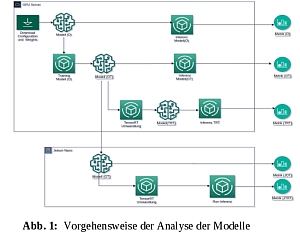
Die Arbeit untersucht das Deployment vortrainierter Detektoren zur Erkennung von Boundingboxen und pixelgenauen Instanzen auf die Plattform Jetson Nano. Hierzu sind geeignete vortrainierte Netze zu evaluieren, weiter zu trainieren und optimiert auf dem Zielsystem auszuführen. Die Optimierung kann auf dem Trainingsserver oder auf dem Zielsystem stattfinden. Die Detektoren sollen in allen drei Phasen durch sinnvolle Metriken auf einer selbstgewählten Datenmenge evaluiert werden. Die lauffähige Umsetzung eines selbst trainierten Detektors auf dem Jetson Nano ist durch eine einfache Rahmenapplikation mit dem Deepstream SDK im Funktionsnachweis zu demonstrieren. Die besondere Schwierigkeit besteht in der Vielzahl beteiligter Frameworks, wie bspw. DeepStream, Triton, CUDA, gsstreamer, TensorFlow, TensorRT, Django, WSGI, Kafka und anderen sowie der Anwendung fortgeschrittener Modelle des Deep-Learnings, wie YOLO, SSD und Mask R-CNN.
Im Ergebnis konnten die Netze erfolgreich auf dem Deep-Learning-Server der Hochschule weitertrainiert und in verschiedenen Kriterien mit den Originalen verglichen werden. Die Optimierung erfolgte auf dem Trainingsserver und zeigte nur wenig Verbesserungen, beim Deployment auf das eingebettete Systeme wurden verschiedene Probleme mit TensorRT (TF-TRT) festgestellt. Die Rahmenapplikation auf dem Jetson Nano demonstriert ein lokales SSD zur Objektdetektion der COCO-Klassen, dessen Ergebnisse über RTSP- und Kafka bereitgestellt werden.

Kolloqium: 13.04.2021
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr. Sven Buchholz
Download: A1-Poster
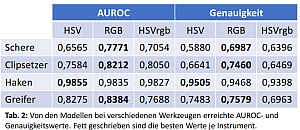
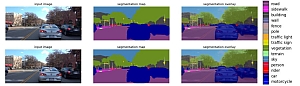
Ziel der Arbeit ist die Untersuchung des Einflusses verschiedener Kodierungen der Farbinformation bei der Klassifikation medizinscher Bilder mit Deep Learning-Modellen. Die Bilder stammen aus einem Operationsszenario der Gallenblasenentfernung und zeigen einzelne oder mehrere Operationswerkzeuge im Körper bei minimalinvasiver Chirurgie. Hierzu sind die Kodierungen zu bestimmen, die Datenmenge vorzuverarbeiten, geeignete Pipelines zur Modellentwicklung und -evaluation zu realisieren und die Ergebnisse auszuwerten. Die besondere Schwierigkeit besteht in der Größe der Datenmenge, der Einarbeitung in das Gebiet der Bildklassifikation mit Convolutional Neural Networks und dem korrekten Umsetzen eines sinnvollen Evaluierungskonzeptes.
Im Ergebnis entstand gelungene Modellierung der Bildklassen unter Berücksichtigung der Besonderheiten der Datenmenge. Die anschauliche Interpretation der Fehlklassifikationen deckte Probleme in der Grundwahrheit Cholec80 auf.
Kolloqium: 13.04.2021
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr. Jochen Heinsohn, Dr. rer. nat. Florian Aspart (caresyntax GmbH)
Download: A1-Poster, Abschlussarbeit

Genetische Algorithmen (GA) können zur Optimierung der Wichtungen künstlicher neuronaler Netze (kNN) verwendet werden. Die Lernaufgabe ist in diesem Fall das Finden einer Policy, die in der Lage ist, in einer einfachen simulierten Umgebung ein Fahrzeug zu steuern und gehört damit zum Reinforcement-Learning. Hierzu ist der GA zu implementieren und auf die Lernaufgabe anzuwenden. Die (physikbasierte) Simulation ist in geeigneter Weise in Unity zu entwickeln und soll Aspekte der Vermittlung von Konzepten berücksichtigen. Dies wäre denkbar durch die Visualisierung der Genotypen, der Fitnessverteilung oder der Fitnessentwicklung. Die besondere Schwierigkeit besteht in der Entwicklung einer Gesamtapplikation mit Simulation, Prozess-Steuerung, Visualisierung und KI-Komponente.
Im Ergebnis entstand eine anschauliche, motivierende Unity/C#-Applikation, die eine Population von neuronalen Netzen als Policy für die Steuerung der Fahrzeuge evolviert. Die Evolution kann mittels Fitnessverteilung und Fitnesskurven über die Generationen verfolgt werden. Die Verwandschaftsverhältnisse werden durch Farbcodes im Genotyp verdeutlicht. Trainierte Populationen können dann auf andere Strecken übertragen werden und zeigen dort eine ähnlich gute Leistung.

Kolloqium: 29.03.2021
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr. Jochen Heinsohn
Download: A1-Poster, Abschlussarbeit
In den letzten Jahren hat die Edge-KI, d.h. die Übertragung der Intelligenz von der Cloud in Edge-Geräte wie Smartphones und eingebettete Systeme an großer Bedeutung gewonnen. Dies erfordert optimierte Modelle für maschinelles Lernen (ML), die auf Computern mit begrenzter Rechenleistung funktionieren können. Die Quantisierung ist eine der wesentlichen Techniken dieser Optimierung. Hierbei wird der Datentyp zur Darstellung der Parameter eines Modells verändert. In dieser Arbeit wurde die Quantisierung untersucht, insbesondere die Quantisierungstechniken nach dem Training, die in TensorFlow Lite (TFLite) verfügbar sind. Ein auf dem MNIST- Datensatz trainiertes Bildklassifizierungsmodell und ein auf dem Cityscapes-Datensatz trainiertes semantisches Segmentierungsmodell wurden für die Durchführung von Experimenten eingesetzt. Für das Benchmarking wurde die Inferenz auf zwei Hardware-unterschiedlichen CPU-Architekturen ausgeführt, und zwar auf einem Laptop und einem Raspberry Pi. Für das Benchmarking wurden Metriken wie Modellgröße, Genauigkeit, mittlere Schnittmenge über Vereinigung (mIOU) und Inferenzgeschwindigkeit gehandhabt. Sowohl für Bildklassifizierungs- als auch für semantische Segmentierungsmodelle zeigten die Ergebnisse eine erwartete Verringerung der Modellgröße, wenn verschiedene Quantisierungstechniken angewendet wurden. Genauigkeit und mIOU haben sich in beiden Fällen nicht wesentlich von der des Originalmodells geändert. In einigen Fällen führte die Anwendung der Quantisierung sogar zu einer Verbesserung der Genauigkeit. Dabei hat sich die Inferenzgeschwindigkeit bezüglich des Bildklassifizierungsmodells adäquat verbessert. In einigen Fällen erhöhte sich die Inferenzgeschwindigkeit auf Raspberry Pi sogar um den Faktor 10.

Kolloqium: 02.03.2021
Betreuer: Prof. Dr.-Ing. Jochen Heinsohn, Abhishek Saurabh (MSc) Volkswagen Car.Software Organization, Dipl. Inform. Ingo Boersch
Download: A1-Poster, Bachelorarbeit
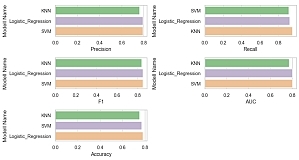
Die Kreditwürdigkeitsprüfung ist ein wichtiger Schritt, der von Kreditvergabestellen durchgeführt wird und der darüber entscheiden kann, ob das Bankinstitut potenziellen Kreditnehmern einen Kredit gewährt oder nicht. Diese Prüfung hat einen großen Einfluss auf Agenturen, insbesondere im Finanzsektor. Um finanzielle Probleme zu vermeiden, die aufgrund von Risiken bei der Kreditvergabe auftreten, wird eine Methode benötigt, die die Kreditwürdigkeitsprüfung unterstützt, indem die statistische Leistung eines Kreditscoring-Modells erhöht wird. Mit Hilfe von maschinellen Lernmodellen können Zeit, Aufwand und Kosten für die Durchführung statistischer Analysen, die auf Big Data angewendet werden, reduziert werden. Aus diesem Grund werden in dieser Arbeit Algorithmen des maschinellen Lernens, namentlich von Logistic Regression, K-Nearest Neighbors und Support Vector Machine, verglichen. Ferner werden Experimente durchgeführt, die die Leistung dieser Modelle verbessern können.

Kolloqium: 11.02.2021
Betreuer: Prof. Dr. Jochen Heinsohn, Dipl.-Inform. Ingo Boersch
Download: A1-Poster
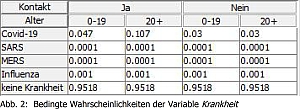
Bayessche Netze (BN) sind gut zur Modellierung von Unsicherheit geeignet. Ein aktuelles Beispiel für das Auftreten von Unsicherheit ist die COVID-19 Domäne, insbesondere die Zusammenhänge zwi- schen u.a. Symptomen, Analysen, Auswirkungen und Folgen. Nach einer kurzen Einführung in die Grundlagen der BN sollen die we- sentlichen Konzepte der COVID-19 Domäne einschließlich ihrer Zu- sammenhänge dargestellt werden. Eine Analyse zum Stand der Forschung zu BN, die genau diese Domäne bereits als Anwendung haben, schließt sich an, ebenfalls eine eigene kurze Bewertung. Kern der Bachelorarbeit ist eine eigene Umsetzung mit Hilfe des HUGIN-Tools.
Die entstandene Anwendung ermöglicht es, die Wahrscheinlichkeit einer Erkrankung an COVID-19, SARS, MERS oder Influenza zu bestimmen. Dafür werden die beobachteten Symptome dem Netz als Evidenz bekannt gemacht. Das heißt, der Wert der entsprechenden Variable wird festgelegt und ist nicht mehr abhängig von der ursprünglichen Wahrscheinlichkeit. Es lässt sich zeigen, dass spezifische Symptome, wie die Störung des Geschmacks und/oder Geruchssinns, die A- posteriori-Wahrscheinlichkeiten der Krankheiten stärker beeinflussen als häufige Symptome wie Husten.

Kolloqium: 11.02.2021
Betreuer: Prof. Dr. Jochen Heinsohn, Dipl.-Inform. Ingo Boersch
Download: A1-Poster
Diese Arbeit stellt Probleme und Lösungen vor, die auftreten können, wenn mit großen unstrukturierten Datensätzen gearbeitet wird. Dies erfolgt am Praxisbeispiel, die über die Zeit verwendeten JavaScript-Bibliotheken aus dem CommonCrawl-Datensatz zu extrahieren. Beginnend mit wenigen Hardware-Ressourcen und dem späteren Einsatz der stärkeren Infrastruktur des Future SOC Labs werden die verschiedenen Probleme, die diese Entwicklungsstadien mit sich bringen, behandelt, bspw. knappe Ressourcen zum Betreiben der Datenbank und die Hardwarekonfiguration. Abschließend werden die gesammelten Erkenntnisse anhand eines Teils des Datensatzes für das Praxisbeispiel umgesetzt und die Ergebnisse visualisiert. Die Einschränkung auf nur einen Teil des Datensatzes resultiert daraus, dass mit der vorhandenen Hardware der komplette Datensatz nicht bearbeitet werden kann.

Kolloqium: 23.10.2020
Betreuer: Prof. Dr. Sven Buchholz, Dipl. Inform. Ingo Boersch
Download: A1-Poster
In diesem Teilprojekt geht es um die Simulation von Evolution in einem künstlichen ökologischen System. Das langfristige Ziel ist eine anschauliche Visualisierung verschiedener Evolutionsphänomene wie bspw. Gendrift, mehrkriterielle Optimierung, dynamische Fitnesslandschaften, Koevolution, konvergente Evolution und andere. Diese Effekte sind in der Natur wegen ihrer Verteiltheit und Langsamkeit schwer zu beobachten und sollen hier durch Individuen in einer 3D-Welt erlebbar werden. Es soll Spaß machen, den Experimenten wie einem spannenden Film zu folgen. Das Projekt orientiert sich an der 2D-Welt in [1].
Phase 1: Schließen der Evolutionsschleife in einer einfachen Ökologie
Lauffähiger Prototyp mit Genotypen, Phänotypen, Bewegung, Mutation, Vererbung und Futter (UnrealEngine, C++ und Blueprint)
Quelltext und Exe auf Anfrage an boersch@th-brandenburg.de.
[1] Ventrella J. (2005) GenePool: Exploring the Interaction Between Natural Selection and Sexual Selection. In: Adamatzky A., Komosinski M. (eds) Artificial Life Models in Software. Springer, London. https://doi.org/10.1007/1-84628-214-4_4
Ziel der Arbeit sind erste Schritte zur Erweiterung einer Angebotsplattform für Leasingverträge um ein Vorschlagssystem. Das bisherige System benutzt einen sog. Dienstwagenrechner (DWR), um die monatliche Kostenbelastung für vom Nutzer einzugebende Vertragsdaten zu berechnen. Die Berech-nung ist zeitaufwändig. Durch eine Beschleunigung des DWR könnte die Zielgröße schon bei teilweise eingegebenen Vertragsdaten für eine Vielzahl von Optionen, bspw. Fahrzeugtypen, berechnet wer-den und somit als Grundlage für einen Vorschlag eines Vertragsmerkmals dienen. Diese Arbeit ver-sucht das Ziel durch eine datenbasierte Approximation des DWR zu erreichen. Die Hauptziele der Arbeit sind somit:

Eine Schwierigkeit der Aufgabe besteht in der Einbettung in einen realen Unternehmenskontext, sowie in der besonderen Situation der COVID-Pandemie.
Kolloqium: 09.07.2020
Betreuer: Dipl. Inform. Ingo Boersch, Prof. Dr. Susanne Busse
Download: A1-Poster

Eine erfolgreiche Kombination von Imitation Learning (IL) und Reinforcement Learning (RL) zur Bewegungssteuerung eines Roboters besitzt das Potenzial, einem Endnutzer ohne Programmierkenntnisse einen intelligenten Roboter zu Verfügung zu stellen, der in der Lage ist, die benötigten motorischen Fähigkeiten von den Menschen zu erlernen und sie angesichts der aktuellen Rahmenbedingungen und Ziele eigenständig anzupassen. In dieser Masterarbeit wird eine Kombination von IL und RL zur Bewegungssteuerung des humanoiden Roboter NAO eingesetzt. Der Lernprozess findet auf dem realen Roboter ohne das vorherige Training in einer Simulation statt. Die Grundlage für das Lernen stellen kinästhetische Demonstrationen eines Experten sowie die eigene Erfahrung des Agenten, die er durch die Interaktion mit der Umgebung sammelt.
Das verwendete Lernverfahren basiert auf den Algorithmen Deep Deterministic Policy Gradient from Demonstration(DDPGfD) und Twin Delayed Policy Gradient (TD3) und wird in einer Fallstudie, dem Spiel Ball-in- a-Cup, evaluiert. Die Ergebnisse zeigen, dass der umgesetzte Algorithmus ein effizientes Lernen ermöglicht. Vortrainiert mit den Daten aus Demonstrationen, fängt der Roboter die Interaktion mit der Umgebung mit einer suboptimalen Strategie an, die er im Laufe des Trainings schnell verbessert. Die Leistung des Algorithmus ist jedoch stark von der Konfiguration der Hyperparameter abhängig. In zukünftigen Arbeiten soll für das Ball-in- a-Cup-Spiel eine Simulation erstellt werden, in der die Hyperparameter und die möglichen Verbesserungen des Lernverfahrens vor dem Training mit dem realen Roboter evaluiert werden können.

Kolloqium: 22.01.2020
Gutachter: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Jochen Heinsohn
Download: A1-Poster, Masterarbeit
Interessante Schlagzeugrhythmen zu finden ist eine kreativ anspruchsvolle Aufgabe. Es gibt die Möglichkeiten verschiedene Instrumente zu verschiedenen Zeitpunkten zu spielen. Die Anordnung der zu spielenden Instrumente in einem Zeitverlauf muss dabei wiederholbar sein und dem Schlagzeuger gefallen. Zur Unterstützung bei diesem Prozess werden interaktive evolutionäre Algorithmen vor- geschlagen. Durch die Interaktivität kann der Nutzer die Suche steuern und die Abwand- lungsoperatoren des evolutionären Algorithmus erzeugen neue Vorschläge. Ein Schwerpunkt dieser Arbeit liegt auf der Benutzeroberfläche. Diese soll die Ermüdung des Nutzers gering halten und auch zur Nachvollziehbarkeit des evolutionären Algorithmus beitragen. Theoretische Grundlagen werden erläutert, inspirierende Arbeiten betrachtet, die Konzep- tion und Umsetzung eines Demonstrationsprogramms beschrieben und Versuche mit dem Programm dokumentiert und ausgewertet.
Evolutionäre Algorithmen sind Optimierungsverfahren, die von der Evolution von Lebewesen inspiriert sind. Es werden Lösungsvorschläge (Individuen) erzeugt, die eine Bewertung (Fitness) zugeordnet bekommen, auf deren Grundlage eine Auswahl (Selektion) stattfindet welche Individuen zur Erzeugung der nächsten Individuen genommen werden. Die Kodierung eines Individuums ist der Genotyp, die Erscheinungsform des Individuums ist der Phänotyp. Wenn es eine Mensch-Maschine-Schnittstelle gibt, dann handelt es sich um einen interaktiven evolutionären Algorithmus nach der erweiterten Definition aus [Tak01]. Die Inklusion des Menschen in den Prozess stellt den Schwachpunkt dieser Vorgehensweise dar, da Menschen durch gleichbleibende Tätigkeiten schnell ermüden. Außerdem stellt das Vergleichen mehrerer zeitsequenzieller Individuen eine besondere kognitive Belastung des Nutzers dar.
[Tak01] Takagi, H.: Interactive evolutionary computation: fusion of the capabilities of EC optimization and human evaluation. In: Proceedings of the IEEE 89 (2001), Nr. 9. http://dx.doi.org/10.1109/5.949485. – DOI 10.1109/5.949485
Kolloqium: 29.10.2019

Gutachter: Dipl.-Inform. Ingo Boersch, Prof. Dr. Martin Christof Kindsmüller
Download: A1-Poster, Masterarbeit
Bei dieser Arbeit sollen anonymisierte, aufgezeichnete Motorradtouren (Tracks) von calimoto Nutzern analysiert werden, um daraus zu ermitteln, wie häufig Motorradfahrer auf welchen Straßen gefahren sind. Daraus soll ein neues Routingprofil erstellt werden, welches Routen über die populärsten Straßen generieren soll. Evaluiert wird auch, ob die Integration der Häufigkeitswerte in die Routenplanung nützlich ist und diese für Motorradfahrer geeignete Routen generiert.
Kolloqium: 18.09.2019

Betreuer: Prof. Dr.-Ing. Jochen Heinsohn, Sebastian Dambeck M.Sc. (calimoto GmbH), Dipl.-Inform. Ingo Boersch
Download: A1-Poster

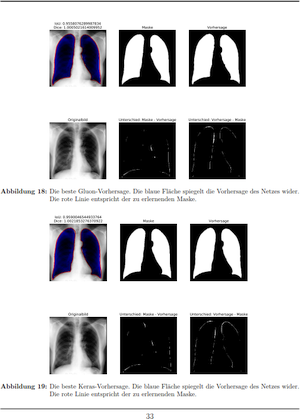
Die Arbeit untersucht exemplarisch die Leistzungsfähigkeit und Anwendbarkeit von GluonCV (Frameworks zur vereinfachten Verwendung tiefer neuronaler Netze) exemplarisch zur semantischen Segmentierung medizinischer Bilddaten mit einem U-Net. Hierzu wird angelehnt an die U-Net-Architektur [RFB15] eine vorhandene Keras-Implementierung [Pet18] in GluonCV reimplimentiert und in systematischen Versuchen verschiedene Kriterien zu Umsetzbarkeit und Performance evaluiert.
[RFB15] Ronneberger, Olaf ; Fischer, Philipp ; Brox, Thomas: U-Net: Convolutional Networks for Biomedical Image Segmentation. In: CoRR (2015).
[Pet18] Petsiuk, Vitali: Lung Segmentation (2D). (Dezember 2018). https://github.com/imlab-uiip/lung-segmentation-2d, Abruf: 05.07.2019.
Kolloqium: 05.09.2019
Gutachter: Prof. Dr. Sven Buchholz, Dipl.-Inform. Ingo Boersch


Ziel dieser Arbeit ist die Untersuchung von Ansätzen zur Stimmungsanalyse von Tweets in deutscher Sprache. Hierzu ist ein Data Mining-Prozess zu durchlaufen mit den Phasen Datenselektion, -exploration, - vorbereitung, Merkmalsgenerierung, Modellierung und Evaluation. Die besondere Schwierigkeit besteht in der Datenbeschaffung, den unstrukturierten Daten (Tweets) sowie der Auswahl und lauffähigen Umsetzung der Lernalgorithmen aus dem Bereich des Deep Learnings. Die Klassifizierer sollen mit ihren Hyperparametern nachvollziehbar dokumentiert und geeignet evaluiert werden.

Kolloqium: 29.03.2019
Betreuer: Prof. Dr. Sven Buchholz, Dipl.-Inform. Ingo Boersch
Download: A1-Poster, Masterarbeit

Beim Erlernen des Klavierspielens kann es besonders für Neueinsteiger problematisch sein, einen guten Fingersatz zu finden. Das Ziel dieser Arbeit ist, ein Programm zu erstellen, das den Fingersatz für Klavierpartituren generieren kann.
Diese Aufgabe wurde über die letzten 20 Jahre mehrfach versucht zu lösen. Die Lösungsansätze basieren meist auf der gleichen Idee und funktionieren nur bei einfachen Klavierstücken. In dieser Arbeit wurde deswegen mit einem anderen Lösungsansatz (Machine-Learning) gearbeitet. Es wurde eine Applikation zur Erzeugung von Fingersatz aus Partituren mit dem aktuellen Verfahren der bidirektionalen LSTM-Netze konzipiert und erfolgreich umgesetzt.
Die besondere Schwierigkeit lag in der Komplexität des gewählten Anwendungsszenarios und den aufwändigen Tests zur Evaluation der Performanz. Aufwändig deshalb, da es zu einer Partitur mehrere gut spielbare Fingersätze geben kann, so dass die automatisch erzeugten Fingersätze durch tatsächliches Spielen bewertet werden müssen.

Kolloqium: 28.09.2018
Betreuer: Prof. Dr. rer. nat. Martin Christof Kindsmüller, Dipl.-Inform. Ingo Boersch
Download: A1-Poster
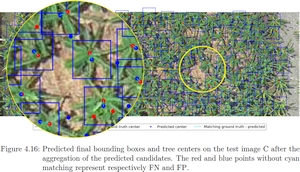
Die Arbeit bearbeitet ein schwieriges Problem bei der automatisierten Überwachung von Pflanzenzuständen auf Bauernhöfen und Plantagen. Sie schlägt eine auf Deep Learning basierende Methode vor, um Bananenbäume auf einer Bananenplantage mittels Drohnenbildern automatisch zu detektieren und zu zählen. Die Schwierigkeit dieser Aufgabe besteht darin, dass sich Bananenbaumkronen sehr oft überlappen. Selbst für einen Menschen ist diese Aufgabe sehr schwierig zu erledigen. Die Aufgabe zerfällt damit in zwei Teile: Lokalisierung (Detektion) und Zählung.
Zur Lösung dieses Problems wird ein mehrstufiger Ansatz verwendet: ein Klassifikator erkennt, ob eine ROI eine Bananenbaumkrone enthält, ein folgender Regressor bestimmt die Koordinaten der Kronenkandidaten in der ROI. Eine abschließende Aggregation fasst die Baumkronenkandidaten zu erkannten Baumzentren zusammen. Diese sind zum Schluss die gesuchten Baumkronen. Die entwickelte Methode wird auf einem Testfall mit vielversprechenden Ergebnissen evaluiert. Auf diesem Testfall, wo dicht gepflanzte Bäume stehen, erreicht das Modell ein Margin- Of-Error von 0.0821. Dies entspricht einer Güte von 91.79% bei der Zählungsaufgabe. Hervorzuheben ist der geringe durchschnittliche Abstandsfehler von etwa 43 cm bei der Lokalisierungsaufgabe.

Kolloqium: 24.09.2018
Betreuer: Prof. Dr.-Ing. Sven Buchholz, Dipl.-Inform. Ingo Boersch, Jan Vogt (Orca Geo Services GmbH, Brandenburg)
Download: A1-Poster
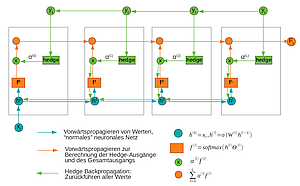
Das Ziel der Arbeit ist die Untersuchung der Eignung von Hedge-Backpropagation zur Vorhersage von Maschinenausfällen auf dem Turbofan-Datensatz. Hedge-Backpropagation ist ein Multilayerperzeptron, bei dem aus jeder versteckten Schicht eine zusätzliche Ausgabe erzeugt wird. Die Ausgaben werden linear gewichtet und ihre Wichtung mit dem Hedge-Algorithmus alternierend zum übrigen Netz angepasst. So soll es möglich sein, dass sich über diese Wichtungen die genutzte Tiefe des Netzes selbständig an die Aufgabe anpasst.
Der Ansatz soll detailliert vorgestellt und entweder selbst oder unter Zuhilfenahme einer geeignet gewählten Implementierung umgesetzt und mit anderen Ansätzen, bspw. LSTM-Netzen nach sinnvoll gewählten Kriterien verglichen werden.

Kolloqium: 06.08.2018
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Sven Buchholz, Prof. Dr. rer. nat. Adrian Paschke (Fraunhofer FOKUS)
Download: A1-Poster
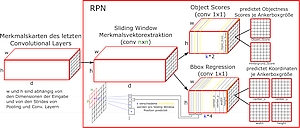
Ziel der Arbeit ist die Untersuchung der Leistungsfähigkeit aktueller künstlicher neuronaler Netze zur Objektdetektion in Bildern. Hierzu sind einführend wesentliche Konzepte des Deep Learnings zu erläutern. Der Schwerpunkt der Arbeit besteht in der Evaluation regionsbasierter Objektdetektionssysteme. Hierzu soll die Funktionsweise mehrstufiger regionsbasierter Detektionssysteme, insbesondere von R-CNN, Fast-RCNN und Faster-RCNN, detailliert erläutert und verglichen werden. Die Netze sind zu implementieren und auf geeigneten Daten, bspw. den VOC-Datenmengen, zu trainieren und der Einfluss von Hyperparametern auf Rechenzeiten und Performance zu untersuchen. Die Evaluationsszenarien und Performancekriterien sind geeignet zu wählen.

Kolloqium: 11.07.2018
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr. Sven Buchholz
Download: A1-Poster, Masterarbeit
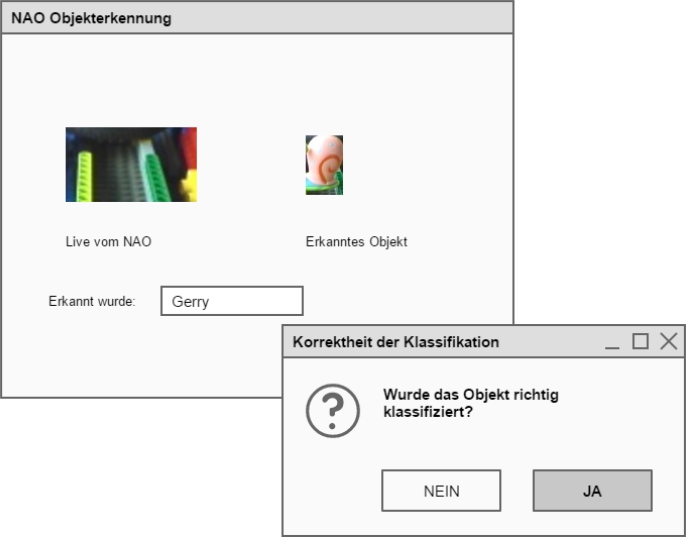
Ziel der Arbeit ist die Entwicklung einer Applikation zur Demonstration der Interaktion einer Person mit einem Roboter zum Erlernen von Objekten, die später wiedererkannt werden sollen. Der Schwerpunkt liegt zum einen auf der Entwicklung des Interaktionsmodells und zum anderen auf einer zuverlässigen Erkennung nach wenigen Lernbeispielen. Die besondere Schwierigkeit liegt in der Verwendung des NAO-Roboters. Die Arbeit soll die Vorarbeiten berücksichtigen und diese weiterentwickeln.
Im Ergebnis entstand eine Python-Applikation, die im Dialog mit einem Menschen in der Lage ist, Objekte zu labeln und wiederzuerkennen. Eine kreative Lösung stellt die robuste Eingabe des Labels über Stempel und Zeichenerkennung dar. Das Wiedererkennen wird durch Segemntierung und Klassifikation gelöst. Die Segmentierung erfolgt pragmatisch anhand eines initialen Hintergrundes, für die Klassifikation werden SIFT-Features als Objektmerkmale extrahiert und damit eine RBF-SVM trainiert.

Kolloqium: 07.03.2018
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr. Jochen Heinsohn
Download: A1-Poster

Ziel der Arbeit ist die Entwicklung einer Applikation zur Demonstration von Reinforcement- Lernen (RL) auf autonomen, humanoiden Robotern. Demonstriert werden soll das Erlernen einer erfolg- reichen Handlungsstrategie in einem einfachen realen Szenario. Das Szenario kann selbst gewählt werden, bspw. das Sortieren von Bällen. Das Szenario soll im Wesentlichen deterministisch, kann aber in seltenen Fällen stochastisch reagieren. Der Lernvorgang soll unbeaufsichtigt selbständig laufen können und in kurzer Zeit (bspw. einer Stunde) zu einer erfolgreichen Policy führen.
Ein zweiter Applikationsmodus soll das unbegrenzte Ausführen der erlernten Policy ermöglichen. Für den Lernvorgang darf der Agent keine fremderstellte Simulation verwenden, für Evaluierung und Test der Applikation ist eine Simulation natürlich erlaubt. Damit besteht die zweite Schwierigkeit in der geringen Anzahl von Interaktionen mit dem realen Szenario, so dass Maßnahmen zur Effizienzsteigerung klassischer RL-Ansätze verwendet werden müssen. Hilfreich wäre eine geeignete Visualisierung des Lernvorganges bzw. der Policy oder transparenter Wertefunktionen, um Besuchern und Studenten den Ablauf zu verdeutlichen und die Programm-Entwicklung zu unterstützen.

Kolloqium: 07.03.2018
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr. Jochen Heinsohn
Download: A1-Poster, Kolloquiumsvortrag, Masterarbeit

Colin Christ studiert seit 2012 Informatik an der TH Brandenburg. Den Bachelor schloss er mit dem Schwerpunkt „Intelligente Systeme“ ab. In seinem Masterprojekt vertiefte er das Thema "Reinforcement Learning (RL)" aus der Vorlesung "Künstliche Intelligenz". Reinforcement Learning ist ein Lernparadigma, das in der Robotik zunehmend Einsatz findet. Hierbei lernt ein Agent durch Ausprobieren eine genau auf seine Situation, bspw. seinen Körper und Sensorik, angepasste Handlungsstrategie. Neue Lernalgorithmen reduzieren die Anzahl notwendiger Interaktionen durch Übertragen erlebter Erfahrungen auf ähnliche Situationen und führen so zu einem verkürzten Lernvorgang. Mittlerweile scheint der Einsatz von RL in industriellen Umgebungen möglich.
Colin Christ behandelt in seiner Masterarbeit ein Szenario, in dem ein humanoider Roboter auf diese Weise vom Menschen definierte Ziele erreichen soll - ohne dass explizit programmiert wird, wie die Aufgabe gelöst werden kann: "Wünsch Dir was"-Programmierung.
Die Zwischenergebnisse präsentierte er kurzweilig und zur Diskussion anregend auf dem World Usability Day zum diesjährigen Thema "Artificial Intelligence" am 09.11.2017 im Infopanel "UX- und Design-Innovationen aus Brandenburg" in Berlin.



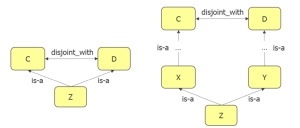
Ziel der Bachelorarbeit ist die Untersuchung einer medizinischen Ontologie (WNC-Ontologie*) im Hinblick auf Inkonsistenzen und die Entwicklung eines Algorithmus zur Reparatur von Inkonsistenzen. Hierzu wurden verschiedene Inkonsistenz-Dimensionen in der vorliegenden Ontologie analysiert und eine Gruppe von Inkonsistenzen definiert, für die eine Reparatur mit einem teilautomatischen Verfahren möglich ist. Dazu werden logisch widersprüchliche Bestandteile der Ontologie in einem Dialog mit dem Domänenexperten disambiguiert und anschließend korrekt modelliert.
*Die WNC-Ontologie wird von dem Berliner Unternehmen ID GmbH & Co. KGaA entwickelt. Sie bildet die in der Wingert-Terminologie dargestellten medizinischen Begriffe als Konzepte und die Zusammenhänge zwischen diesen Begriffen als Relationen ab und entstand als Ergebnis der Migration der Wissensrepräsentation aus einem semantischen Netz in eine moderne Ontologie basierend auf Beschreibungslogik.

Kolloqium: 21.09.2017
Betreuer: Prof. Dr.-Ing. Jochen Heinsohn, Dipl.-Inform. Ingo Boersch
Download: A1-Poster
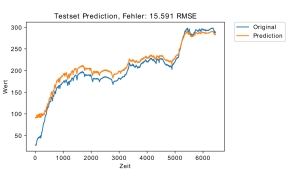
Ziel der Arbeit ist die Untersuchung, ob und wie gut sich LSTM-Netze zur Prognose von Motorsignalen eignen.
LSTM-Netze sind rekurrente künstliche neuronale Netze mit einem besonderen Neuronenmodell. Diese Netze eignen sich zur Prognose (Zeitreihen, Sprachverarbeitung) oder als Generator insbesondere dann, wenn sich die relevanten Informationen in weiter Vergangenheit befinden.
Die Arbeit untersucht das Verhalten der Netze auf künstlichen Zeitreihen und auf realen Signalen im Holdout-Verfahren. Verwendet wird das Deep Learning-Framework Keras auf TensorFlow, allerdings ohne GPU-Unterstützung.
Es konnte gezeigt werden, dass LSTM in der Lage sind, dynamische Motorprozesse zu erlernen und erfolgreiche Prognosen durchzuführen. Die Prognose mit LSTM lieferte in den untersuchten Fällen in diesem ersten Pilotprojekt ohne jede Optimierung ähnlich gute Ergebnisse, wie die bereits bei IAV etablierten Modelle, ist aber im Training deutlich aufwändiger.
Kolloqium: 21.09.2017
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Jochen Heinsohn, Dipl.-Ing. Frank Beyer (IAV GmbH)
Download: A1-Poster

Ziel der Arbeit ist ein Softwarefilter zum Entfernen der Bewegungsunschärfe in Fotos, die durch Bewegen der Kamera während der Aufnahme entstanden ist. Diese Unschärfestörung lässt sich vereinfacht als Faltung des Bildes mit einem Bewegungs-Kernel und additivem Rauschen modellieren. Gelingt es den richtigen Kernel zu finden, so kann in einer Optimierungsaufgabe das ungestörte Bild restauriert werden.
Hierzu wir in Anlehnung an ein in [Xu10] publiziertes Verfahren ein eigener vereinfachter Algorithmus entwickelt, der sich iterativ durch Herausarbeiten der Original-Kanten und Optimierung einem geeigneten Kernel nähert. Das Filter wird als Softwareprototyp in Java implementiert und als Plugin in die Bildverarbeitungssoftware Fiji eingefügt. Das Plugin soll für die Restauration von Grauwertbildern verwendet werden. Die Qualität der Restaurationsergebnisse und die Laufzeit des entstandenen Filters werden in drei Testszenarien (zwei mit bekannten Kerneln, ein reales Bild) analysiert. Das Verfahren wurde erfolgreich evaluiert.
[Xu10] Li Xu, Jiaya Jia: Two-Phase Kernel Estimation for Robust Motion Deblurring. ECCV (1) 2010: 157-170

Kolloqium: 08.08.2017
Betreuer: Prof. Dr. sc. techn. Harald Loose, Dipl.-Inform. Ingo Boersch
Download: A1-Poster
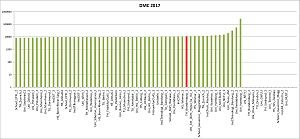
Auch in diesem Jahr beteiligten sich zwei Teams der Technischen Hochschule Brandenburg am Data Mining Cup der prudsys AG, einem Studentenwettbewerb zur intelligenten Datenanalyse. Mit 202 Hochschulen aus aller Welt erreichte die Teilnehmerzahl einen neuen Rekord. Die Aufgabe aus dem Feld "Dynamic Pricing" bestand in der Prognose einer Kundentransaktion einer Online-Apotheke. Dazu standen reale Daten über einen Zeitraum von 3 Monaten zur Verfügung, während der nachfolgende Monat vorhergesagt werden sollte.
Die Aufgabe ähnelt den Aufgaben der vergangenen Jahre, bei denen klar wurde, dass weniger die Optimierung des Lernverfahrens als insbesondere die Merkmalsgenerierung zu guten Ergebnissen beiträgt. Diese ist jedoch kaum automatisierbar und arbeitsintensiv, so dass es für die beiden Masterstudenten Mario Kaulmann und Herval Bernice Nganya Nana viel zu tun gab. Vermutlich ging es vielen Teams ähnlich, denn von den 202 Anmeldungen schafften es nur 66(!) Teams eine Lösung einzureichen, von denen aufgrund ungewöhnlicher Formatanforderungen noch 11 ungültig waren. Unter den 55 gültigen Lösungen errang das THB-Team den Platz 42, passend für Informatiker. Die zweite Einsendung erfolgte leider eine Minute zu spät und hätte Platz 38 erreicht.
Masterprojekt auf der NWK18: Der freie Wille eines Menschen ist eine urbane Hypothese und Inhalt angeregter Forschungstätigkeit. Dabei steht die Frage im Mittelpunkt, ob ein freier Wille existiert oder der Mensch durch das Unterbewusstsein gesteuert ist. Im Rahmen dieser Arbeit wird ein Experiment aus dem Bereich Mensch-Roboter-Interaktion entworfen und vorbereitet, das klären soll, ob der Mensch beim Versuch bewusst zufällig zu handeln, doch unbewusst in ein Muster verfällt. Die Voruntersuchung klärt kritische Probleme und begründet die Zuversicht in die Determiniertheit anhand der Prognose einer Zeitreihe menschlicher Aktionen.
Der Vortrag zur Publikation wird von Vanessa Vogel am 31. Mai 2017 an der Hochschule Mittweida gehalten.
Vogel, Vanessa ; Boersch, Ingo: Prognose des freien Willens - Machbarkeit und erste Ergebnisse. In: 18. Nachwuchswissenschaftlerkonferenz (NWK), Hochschule Mittweida, 2017 (Scientific Reports Nr. 1), S. 341-345. ISSN 1437-7624
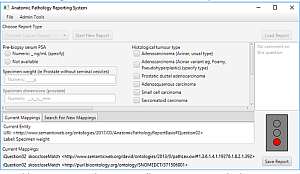
Diese Arbeit beschreibt einen Ansatz, nach dem pathologische Befundberichte strukturiert und vollständig erstellt werden können.
Die implementierte Software nutzt Vorlagen der ICCR (International Collaboration on Cancer Reporting), um ein formales Modell der drei Report-Typen zur Erstellung von Endometrium-, Haut- und Prostatakrebsbefundberichten zu erstellen. Bei den erzielten Dokument-Repräsentationen handelt es sich um Wissensbasen, welche in der Web Ontology Language (OWL) formuliert und somit nicht nur maschinenlesbar, sondern darüber hinaus maschinenverständlich sind. Durch die formal spezifizierte Semantik des entsprechenden Formats lassen sich die Berichte unter Verwendung des HermiT-Reasoners auf Vollständigkeit überprüfen. Des Weiteren wird die Verknüpfung der modellierten Report-Bestandteile zu externen medizinischen Wissensbasen wie SNOMED CT, NCIT und PathLex betrachtet.
Die Beschreibung des ontologiebasierten Verfahrens und die prototypische Implementierung des Softwaretools sollen eine mögliche Darstellungsform aufzeigen, nach der Befundberichte im Bereich der anatomischen Pathologie digital, dynamisch sowie durch vorgegebene Strukturelemente präzise und vollständig erstellt und verarbeitet werden können.

Kolloqium: 10.04.2017
Betreuer: Prof. Dr.-Ing. Jochen Heinsohn, Dipl.-Inform. Ingo Boersch
Download: A1-Poster, Masterarbeit

Ziel der Arbeit ist eine Applikation zur Menüplanung unter Verwendung ontologischen Wissens aus verschiedenen Quellen.
Ein Schwerpunkt ist die Auswahl und integrative Vernetzung geeigneter Wissensquellen in Form von Terminologien zur Beschreibung der Anforderungen an einen gewünschten Menüplan. Hierzu gehören beispielsweise Rezepte, Nährstoffangaben und diätische Restriktionen. Es soll der CTS2-Terminologieserver des Fraunhofer FOKUS verwendet werden.
Ein zweiter Schwerpunkt ist die Formalisierung des Planungsproblems sowie die Auswahl und lauffähige Umsetzung eines geeigneten Optimierungsverfahrens zur Mehrzieloptimierung. Hierbei ist der Stand der Technik einzubeziehen. Die Qualität der erstellten Pläne wird evaluiert.
Die Analyse, Konzeption und Umsetzung ermöglichen, dass aufbauend auf der Arbeit reale Planungsprobleme des Diskursbereiches gelöst werden können. Die Webapplikation läuft in einem aktuellen Browser und erlaubt in prototypischer Weise das Darstellen der Terminologien, die Eingabe des Planungsproblems, die Parametrierung der Planung und die Visualisierung der Ergebnisse. Die Schwierigkeit der Arbeit besteht in Komplexität und im Umfang der notwendig zu lösenden Teilaspekte.
Kolloqium: 24.03.2017
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr. rer. nat. Rolf Socher, in Kooperation mit dem Fraunhofer FOKUS
Download: A1-Poster, Masterarbeit

In dieser Arbeit werden in einem mit Drohnen aufgenommenen, orthorektifizierten Luftbild Bananenpflanzen detektiert und abschließend gezählt. Die Aufgabe fällt damit in das Gebiet der Mustererkennung und soll durch Ansätze des maschinellen Lernens in einem Data-Mining-Prozess gelöst werden. Die besondere Schwierigkeit besteht in der starken Überlappung der Bananenpflanzen im Bild, wodurch eine Segmentierung schwierig bis unmöglich wird. Ebenso kann bei einer entwickelten Plantage nicht mehr von einer gitterförmigen Anordnung der Pflanzen ausgegangen werden.
Ausgehend von einer Menge manuell annotierter Bananen-Templates werden Merkmale von Bildpunkten entwickelt,die es ermöglichen sollen, mit Hilfe von Supervised Learning die Zentren der Pflanzen von anderen Bildpunkten zu separieren. Es werden verschiedene Merkmale (Farbe, Textur, Gray-Level Co-Occurrence Matrix) und Lernalgorithmen systematisch untersucht.

Kolloqium: 27.02.2017
Betreuer: Prof. Dr.-Ing. Sven Buchholz , Dr. Frederik Jung-Rothenhäusler (ORCA Geo Services), Dipl.-Inform. Ingo Boersch
Download: A1-Poster

Beim Widerstandspunktschweißen werden dünne Bleche durch hohe Ströme im Kiloampere-Bereich punktuell miteinander verschweißt. Haupteinsatzgebiet des Fügeverfahrens sind Kraft- und Schienenfahrzeugbau, bei denen diese Verbindungen sicherheitskritischen Anforderungen genügen müssen. Trotz intensiver Forschung auf dem Gebiet ist kein hinreichend zuverlässiges Verfahren bekannt, die Güte der Schweißverbindung zerstörungsfrei zu bestimmen.
Da die Güte der Verbindung wesentlich durch den Verschleiß der Elektrodenkappen mitbestimmt wird, werden die Elektroden mit einem großen Sicherheitspuffer nachgefräst oder gewechselt. Wir stellen einen Ansatz vor, wie ein wesentliches Qualitätsmerkmal - der Punktdurchmesser - mit Prognoseverfahren anhand von Prozessgrößen hinreichend zuverlässig geschätzt und so die Elektrodenlebensdauer erhöht werden kann.
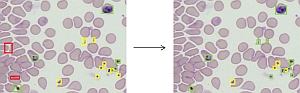
Ziel der Arbeit ist eine Untersuchung numerischer und strategischer Parameter bei der Anwendung von Autoencodern zur Erkennung von Anomalien in Bildern. Hierbei sind systematisch die Einflüsse verschiedener Einstellungen zu evaluieren und zu bewerten. Im Ergebnis soll eine Empfehlung zur Einstellung des Verfahrens bei der Detektion Malaria-infizierter Blutzellen vorgenommen werden. Die besondere Schwierigkeit der Arbeit besteht in der Umsetzung eines systematischen Suchprozesses in einem umfangreichen Parameterraum, der Arbeit mit realen Daten und dem aufwändigen Training.
Kolloqium: 14.10.2016
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Sven Buchholz, Dr.-Ing. Christian Wojek (Carl Zeiss AG)
Download: A1-Poster

Ziel der Arbeit ist die Entwicklung einer Applikation, die einem NAO-Roboter ermöglicht, autonom Tic- Tac-Toe gegen einen menschlichen Spieler zu spielen. Schwerpunkt ist hierbei ein natürliches und motivierendes Spielerlebnis. Hierzu ist es notwendig, robuste Lösungen für Teilprobleme der Interaktion wie Rezeption und Aktorik zu entwickeln, die diese Zielstellung berücksichtigen. Eine leistungsfähige Spielstrategie ist so umzusetzen, dass sowohl starke wie auch schwächere Spieler Freude an der Interaktion finden. Die Applikation soll autonom auf dem Roboter laufen und perspektivisch für andere Spiele sowie beim Spiel NAO gegen NAO einsetzbar sein. Die besondere Schwierigkeit der Arbeit liegt in der Gestaltung der Interaktion und dem Lösen der Robotik-Probleme in einer realen, stochastischen Welt.
Die Arbeit wurde in die Problemfelder Spiellogik, Strategie, Aktorik, Bildverarbeitung und Interaktion aufgeteilt. Spiellogik und Strategie beschäftigen sich mit der Umsetzung des grundlegenden Spielablaufs. Die Aktorik dient primär der Umsetzung des Zeichnens auf dem Spielfeld. In der Bildverarbeitung wird das Spielfeld mit Hilfe der Roboterkameras erfasst und ausgewertet. In der Interaktion wird eine auf Sprache basierende Schnittstelle mit dem menschlichen Gegenspieler sowie eine adaptive Spielstärke umgesetzt.
Kolloqium: 02.08.2016
Betreuer: Prof. Dr.-Ing. Jochen Heinsohn, Dipl.-Inform. Ingo Boersch
Download: A1-Poster

Ziel der Arbeit ist das Erstellen gültiger, transparenter, prädiktiver Modelle zur Vorhersage patientenorientierter Zielgrößen (poZg), wie bspw. dem Überleben von Brustkrebspatientinnen, aus den Daten des Tumorzentrums. Die Analyse dient insbesondere dem Aufzeigen bisher unbekannter Zusammenhänge, Einflussgrößen und Mustern, die zur Verbesserung des Behandlungsprozesses dienen können und mit Ärzten diskutiert werden können. Die Ergebnisse sind in ihrer Güte anhand der vorliegenden Daten geeignet zu bewerten und durch Fachexperten (Ärzte, TZBB) zu evaluieren.
Zugehörige Aufgabenstellungen sind unter anderem: Definition patientenorientierter Zielgrößen, deskriptive und explorative Analyse, Bestimmung relevanter Merkmale, Merkmalsdefinition, Modellbildung und Evaluierung.
Ein zweiter Schwerpunkt ist die geeignete patientenorientierte Visualisierung von Zusammenhängen, die bei Entscheidungen des Patienten hilfreich sein können. Besondere Schwierigkeiten der Arbeit sind die Umsetzung des Data Mining Prozesses mit realen, unvollständigen, fehlerbehafteten Daten und die Nutzung transparenter Modellierung und Visualisierung zum Erkenntnisgewinn für Fachexperten und zur Entscheidungsunterstützung für Patienten. Alle Softwaremodule sollen auf Wiederverwendbarkeit, auch durch Anwender beim TZBB, ausgelegt sein, vorzugsweise soll Python verwendet werden.
Kolloqium: 13.06.2016
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Sven Buchholz
Download: A1-Poster

Masterstudent Patrick Rutter demonstrierte am 1. juni bei der Projektkonferenz der THB, die Fähgikeiten des von ihm programmierten NAO-Roboters beim TicTacToe-Spiel gegen Besucher. Mithilfe eines verlängerten Fingers setzt der NAO auf einen Touchscreen sein Feld und erkennt die Züge des Menschen. Während des Spieles versucht er zwar zu gewinnen, aber nicht demotivierend oft. Er adaptiert sich dazu an die Spielstärke des menschlichen Spielers und erzeugt so ein kurzweiliges Spielerlebnis.
Die Präsentation zeigt einen Zwischenstand der Masterarbeit.


Vom 19. bis 21. Mai trafen sich Professoren, Mitarbeiter und Studenten norddeutscher Fachhochschulen zum zwanglosen Austausch über Forschung und Lehre beim 21. Norddeutschen Kolloquium für Informatik an Fachhochschulen (NKIF 2016) an der HAW Hamburg. Für die TH Brandenburg stellte Franziska Krebs (Masterstudentin Informatik) ihre Zwischenergebnisse zum SmartMenu-Projekt vor, in dem eine Speiseplanung gestützt auf Ontologien und semantische Technologien vorgenommen wird.
Vortragsfolien: Aufbau eines Wissensnetzes für ein klinisches Speiseempfehlungssystem – ein Beispiel aus dem THB-Forschungs-/Projektstudium
Es wurden Kontakte geschlossen und aufgefrischt, gefachsimpelt und diskutiert.

Ziel der Arbeit ist Reflektion und Analyse der Therapieentscheidung im realen Behandlungsprozess des Mammakarzinoms. Dafür soll zunächst ein normatives Modell, welches aus der S3-Leitlinie (LL) gewonnen wird, mit den tatsächlichen Gegebenheiten, gegeben durch epidemiologische Daten des Tumorzentrums Land Brandenburg e.V., verglichen werden.
Zugehörige Fragestellungen sind hierbei: in wie weit wurde die LL eingehalten, wo gibt es Abweichungen, wie groß sind die Abweichungen. Anschließend sollen datenbasiert verschiedene Modelle und Visualisierungen mit Methoden des Data Minings erstellt werden. Diese sollen die reale Therapieentscheidung widerspiegeln. Wichtige Fragestellungen für die anschließende Reflektion und Analyse sind: wo gibt es Überschneidungen und Unterschiede zum LL-Modell, worauf lassen sich die Unterschiede zurückführen, gibt es andere Einflussfaktoren als in der Leitlinie verzeichnet.
Die besondere Schwierigkeit der Arbeit liegt in der Datenqualität und der komplizierten Anwendungsdomäne.
Kolloqium: 07.04.2016
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr. med. Eberhard Beck
Download: A1-Poster
 Sebastian Busse stellt seine Projektarbeit im Rahmen einer
Posterpräsentation vor. (Foto: Dennis Wagner)
Sebastian Busse stellt seine Projektarbeit im Rahmen einer
Posterpräsentation vor. (Foto: Dennis Wagner)
Im Masterprojekt "Künstliche Intelligenz" arbeitet Sebastian Busse an einem System zur Überprüfung von pathologischen Befundberichten auf inhaltliche Vollständigkeit mit Hilfe von terminologischem Wissen. Die erstellte Publikation [1] reichte er beim LOUHI*-Workshop 2015 in Lissabon ein. Der Workshop ist der Teil der EMNLP**-Konferenz.
„Congratulations, your submission has been accepted to appear at the conference.“
Der Fachbereiche Informatik und Medien (FBI) unterstützt Studenten bei Konferenzbeiträgen bei Reisekosten und Tagungsgebühr, um den Einstieg in den Konferenzbertireb zu fördern. So konnte Sebastian Busse seine Arbeit erfolgreich dem wissenschaftlichen Diskurs in Portugal stellen.
* Sixth Workshop on Health Text Mining and Information Analysis
** Conference on Empirical Methods in Natural Language Processing/
[1] Busse, S. Checking a structured pathology report for completeness of content using terminological knowledge. Proceedings of the Sixth International Workshop on Health Text Mining and Information Analysis. 2015 Sep; 103-108

Die Firma mapegy erzeugt für ihre webbasierte Analyse-und Visualisierungssoftware mapegy.scout verschiedene Visualisierungen auf Basis mehrerer Datenquellen wie beispielsweise Patentdaten und wissenschaftliche Publikationen. Eine der Visualisierungen ist eine Patentlandkarte, welche auf Grundlage der benutzerabhängigen Eingabe eine Gruppierung der Patente durchführt (Clusteranalyse) und diese Gruppen auf einer Karte darstellt (Dimensionsreduktion), so dass ähnliche Patente nahe zusammenliegen und unterschiedliche weiter auseinander. Dieser Prozess soll grundlegend überarbeitet werden, damit
Zur Erzeugung der Themenlandkarten wurde eine GHSOM (Growing Hierarchical Self-Organizing Map) gewählt, deren einzelne Teilkarten aus einer Menge von Neuronenmodellen bestehen, die sich an die Trainingsdaten anpassen und somit Clustering und Dimensionsreduktion gleichzeitig realisieren.
Kolloqium: 15.09.2015
Betreuer: Dipl.-Inform. Ingo Boersch, Uwe Kuehn, M.Sc. (mapegy GmbH, Berlin)
Download: A1-Poster

Ziel der Arbeit ist die Entwicklung einer Applikation, die einen NAO-Roboter gegen einen Menschen Tic-Tac-Toe spielen lässt. Perspektivisch soll auch ein Spiel zwischen NAO-Robotern möglich sein. Ein Schwerpunkt der Arbeit ist die geeignete Realisierung eines Lernvorganges, mit dem die Applikation eine Spielstrategie erlernt, bspw. mit Reinforcement-Lernen. Der Lernvorgang soll durch die Messung der Spielstärke evaluiert werden. Wünschenswert ist eine Anzeige der aktuellen Spielstärke.
Die Applikation soll modular entworfen werden, so dass ein einfacher Austausch oder Erweiterung von Komponenten ermöglicht wird. Es soll möglich sein, ein verwandtes Spiel, wie 4x4-Tic-Tac-Toe, umzusetzen, in dem im Wesentlichen nur die spielabhängigen Anteile (wie Spielregeln, Situationserkennung, Zugausführung und Testgegner) modifiziert werden. Die Komponenten Spielsteuerung und Lernmodul sollen möglichst unabhängig vom konkreten Spiel sein.
Eine Teilaufgabe besteht in der Erkennung der Spielsituation mit Hilfe der Bildverarbeitung. Die relative Lage des Spielfeldes zum Roboter kann hierbei als statisch und bekannt vorausgesetzt werden. Sie ist im Rahmen der Arbeit geeignet zu definieren. Zur Ansteuerung der Aktorik ist eine sinnvolle, einfache Schnittstelle unter Berücksichtigung der NAO-Plattform zu realisieren. Die Applikation und Ergebnisse sind in geeigneter Weise zu evaluieren.
Kolloqium: 14.09.2015
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Jochen Heinsohn
Download: A1-Poster

Die zunehmende Verwendung von Ontologien im klinischen Bereich ist eine Herausforderung für das Gebiet der Onotologie-Evolution. In Anwendungsfällen mit eigenständigen Konzeptualisierungen kann es sinnvoll sein, Ontologien zu verwenden, die durch den Fachexperten erweiterbar sind und die Möglichkeit bieten, das Wissensmanagement direkt in die medizinischen Prozesse zu integrieren. Ein Beispiel ist die Erleichterung der Patientenauswahl für medizinische Studien durch das Studienpersonal. Dabei soll den Experten die Möglichkeit geboten werden, ihre Ontologien in einem redaktionellen Prozess selbständig zu pflegen.
Ziel dieser Arbeit ist die Konzeption und Realisierung einer prototypischen Client-Server-Applikation zur Umsetzung von elementaren Operationen der Ontologie-Evolution als REST-Webservice im Kontext der „Health Intelligence Plattform“ (HIP) für das Wissensmanagement in Krankenhäusern.
Kolloqium: 09.09.2015
Betreuer: Dipl.-Inform. Ingo Boersch, Dr. Christian Seebode (ORTEC medical GmbH)
Download: A1-Poster
 Auch in diesem Jahr ist der Fachbereich Informatik und Medien mit zwei
Teams beim Data Mining Cup (DMC) - einem der größten
internationalen Studentenwettbewerbe für intelligente Datenanalyse – im
Rennen. Es ging um Couponing im Handel: anhand historischer
anonymisierter Bestelldaten eines realen Onlineshops mit zugehörigen
Couponausspielungen sollten die Teilnehmer vorhersagen, ob ein Coupon
eingelöst wird oder nicht.
Auch in diesem Jahr ist der Fachbereich Informatik und Medien mit zwei
Teams beim Data Mining Cup (DMC) - einem der größten
internationalen Studentenwettbewerbe für intelligente Datenanalyse – im
Rennen. Es ging um Couponing im Handel: anhand historischer
anonymisierter Bestelldaten eines realen Onlineshops mit zugehörigen
Couponausspielungen sollten die Teilnehmer vorhersagen, ob ein Coupon
eingelöst wird oder nicht.
Studierende im Masterstudiengang Informatik der Fachhochschule Brandenburg (FHB) haben dazu ein treffsicheres Modell entwickelt. Die Vorverarbeitung und Merkmalsbestimmung aus den Daten war diesmal besonders aufwändig, die Masterstudenten setzten dazu freie Werkzeuge ein und programmierten die Algorithmen in den Sprachen R und Python.
Im Gesamtranking belegten die beiden teilnehmenden Teams der FHB mit ihren Lösungen nun schon das zweite Jahr in Folge hervorragende Plätze.
„Ich freue mich mit unseren Teams über die sehr guten Platzierungen“, so Prof. Dr. Sven Buchholz. „In diesem Jahr war die Aufgabe besonders schwer. Wir sind die beste Fachhochschule und haben viele Universitäten hinter uns gelassen.“
Insgesamt landeten die beiden Teams der FHB in diesem Jahr auf den Plätzen 11 und 14. Am Data-Mining-Cup 2015 Ende Juni in Berlin nahmen 188 Teams von 153 Hochschulen aus 48 Ländern teil.
An der Fachhochschule Brandenburg ist Data Mining als Wahlpflichtfach und im Forschungs-/Projektstudium des Masterstudiengangs Informatik verankert. Der viersemestrige Masterstudiengang bietet die Möglichkeit, vorhandenes Informatikwissen in den Bereichen der angewandten Informatik sowie in der Medizininformatik zu vertiefen.

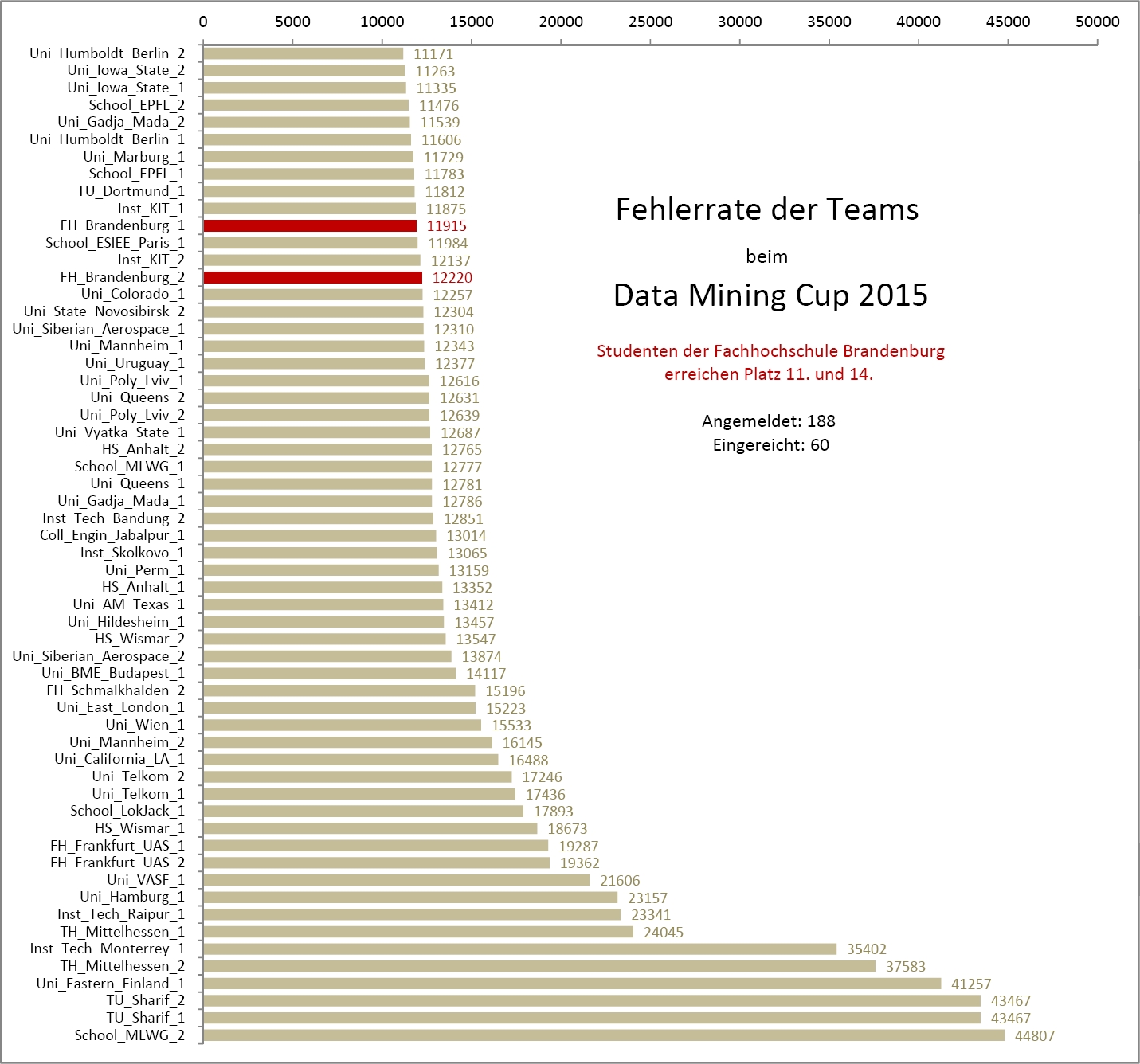
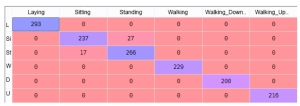 In der Wahlpflichvorlesung "Data Mining" im zweiten Mastersemester der
Informatik wird neben knackigen Vorlesungen und Übungen auch eine Data
Challenge geboten, bei der eine echte Datenanalyse im Team mit freier
Wahl der Mittel bearbeitet und als Paper beschrieben wird. In einem
paarweisen Review-Prozess werden die erstellten Analysen durch die
Studierenden selbst nach vorgegebenen Kriterien evaluiert.
In der Wahlpflichvorlesung "Data Mining" im zweiten Mastersemester der
Informatik wird neben knackigen Vorlesungen und Übungen auch eine Data
Challenge geboten, bei der eine echte Datenanalyse im Team mit freier
Wahl der Mittel bearbeitet und als Paper beschrieben wird. In einem
paarweisen Review-Prozess werden die erstellten Analysen durch die
Studierenden selbst nach vorgegebenen Kriterien evaluiert.
Die Aufgabe dieses Semesters ist die Konstruktion eines Modells, das die Aktivität einer Person (Sitzen, Liegen, Laufen usw.) aus den Messungen ihres Smartphones erkennt. Es sind belastbare Aussagen zur erwarteten Güte des Modells zu treffen und das Modell auf unbekannte Daten anzuwenden. Die Daten stammen aus [1] und sind vorverarbeitet, um sie leichter in Python, R oder RapidMiner laden zu können.
Bei den erstellten Klassifikationen gibt es kein Schummeln, denn die Lehrenden können erkennen, ob die berechneten Vorhersagen mit der Realität übereinstimmen. Dass die Studierenden die Aufgabe in der Mehrheit hervorragend gelöst haben, zeigt die Abbildung der Erfolgsraten, also der Anteil der richtig erkannten Tätigkeiten.
Abb.: Wie gut können die Teams die Tätigkeit einer Person anhand der Smartphone-Daten vorhersagen:
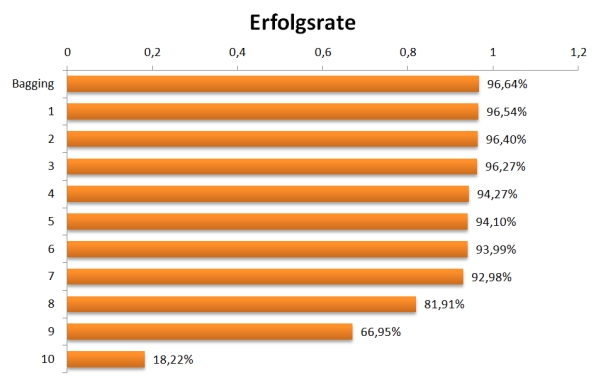
[1] Davide Anguita, Alessandro Ghio, Luca Oneto, Xavier Parra and Jorge L. Reyes-Ortiz. A Public Domain Dataset for Human Activity Recognition Using Smartphones. 21th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, ESANN 2013. Bruges, Belgium 24-26 April 2013.

Am 17. Juni herrschte wieder reges Treiben im Vorraum der Mensa: dort zeigten 43 Studierende aus 11 Teams ihre Projektarbeiten auf der diesjährigen 4. Projektkonferenz.
Aus dem Labor für Künstliche Intelligenz präsentierte Andy Klay eine Arbeit zum Reinforcement-Lernen von Spielstrategien in humanoiden Robotern: der NAO-Roboter Eve erkennt mittels Bildverarbeitung die Spielsituatuin eines Tic Tac Toe-Spiels und reagiert mit einem eigenen Spielzug. Die dazu nötige Spielstrategie wurde jedoch nicht fest implementiert, sondern wird durch den Roboter beim Spielen gegen menschliche und künstliche Gegenr entwickelt, in dem er versucht herauszufinden, in welchen Situation, welche Züge zu einem späteren Spielgewinn führen. Schwache Gegner wird er versuchen auszutricksen und von starken Gegnern wird er Strategien übernehmen.
Reinforcement-Lernen ist in der Grundidee ein einfaches Lernparadigma, bei dem der Lerner nicht passiv die Belehrung durch den Lehrer hinnimmt (wie beim supervised learning), sondern aktiv durch eigene Aktionswahl seinen Lernprozess steuert. Der Lerner erntscheidet also, welche neuen Erfahrungen er machen möchte oder ob er lieber bei bewährten Aktionen bleibt. Die praktische Umsetzung wird schwierig, wenn die Umgebung stochastisch reagiert, nur schwer zu erkennen ist, einen Gegner enthält, sehr viele Zustände umfasst oder die Belohnung/Bestrafung verzögert erfolgt. Mindestens zwei dieser Merkmale weist das Tic Tac Toe-Spiel auf.
NAO und Eve vorm KI-Labor:


Ziel der Arbeit ist die Evaluation von Algorithmen zur Schlagwort-Extraktion aus Dokumenten. Gesucht wird eine Methode, die sich im Kontext der Erstellung von Technologie-Übersichtskarten aus u.a. Patentschriften zur möglichst eindeutigen Beschreibung einzelner Dokumente oder Dokumentmengen eignet. Kriterien zur Abbildung von Beschreibungsgüte und Performanz sollen geeignet definiert und erhoben werden. Ausgewählte Algorithmen sollen in einem SE-Prozess umgesetzt werden. Eine besondere Schwierigkeit der Aufgabe ergibt sich durch die Arbeit mit realen Datenmengen (Stemming, Stoppworte etc.).
Anforderungen an die Algorithmen sind der Umgang mit großen Datenmengen, Laufzeit und das Finden geeigneter Schlüsselworte und –Phrasen. Es werden drei Anwendungsfälle (Suche in Daten, Clustern, Keyword-Cloud) unterschieden. Fünf Algorithmen aus dem Bereich der unüberwachten Extraktion werden dargestellt, implementiert und evaluiert. Es erfolgt eine Aufteilung in zwei Klassen, je nachdem, ob zur Schlagwort-Bestimmung eines Dokumentes die gesamte Dokumentenmenge berücksichtigt wird (TFIDF, CorePhrase) oder nicht (TextRank, Rake, statistische Kookkurrenz-Auswertung). Abschließend erfolgt nach einer Komplexitätsabschätzung die Umsetzung zweier Ansätze in einsatzbereite RapidMiner-Operatoren.
Kolloqium: 09.04.2015
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr. rer. nat. Gabriele Schmidt, Uwe Kuehn M. Sc. (mapegy GmbH)
Download: A1-Poster
 Evaluation von Real-Time Appearance-Based Mapping zum Simultaneous
Localization and Mapping mit RGB-Depth-Sensorik unter dem Robotic
Operating System
Evaluation von Real-Time Appearance-Based Mapping zum Simultaneous
Localization and Mapping mit RGB-Depth-Sensorik unter dem Robotic
Operating System
Ziel der Arbeit ist die Evaluation des SLAM-Verfahrens RTAB-Map. Das Verfahren integriert aufeinanderfolgende Tiefenbilder eines Kinect-Sensors mit Hilfe einer Korrespondenzanalyse in den zugehörigen Farbbildern zu einer farbigen Punktwolke. Das Verfahren soll im Detail erläutert werden.
Zur Evaluation sind geeignete Kriterien anhand von Anwendungsszenarien zu definieren und in Versuchen zu prüfen. Das Schließen von Positionsschleifen, also das Wiedererkennen schon besuchter Orte soll berücksichtigt werden. Anwendungsszenarien können sein: SLAM auf dem Pioneer-Roboter, 3D-Modellierung durch freie Bewegung, Modellierung von Gebäuden, Beobachtung dynamischer Objekte (Personen, Roboter, Drohnen) durch mehrere Kinect-Sensoren. Die Installation unter der aktuellen ROS-Version soll nachvollziehbar dargestellt werden. Die besondere Schwierigkeit der Arbeit liegt beim Einarbeiten in teilweise komplizierte Ansätze aktueller Robotertechnologien und beim Umsetzen in lauffähige Expe rimente.
Kolloqium: 14.11.2014
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Jochen Heinsohn
Download: A1-Poster
 Evolution regulärer Ausdrücke zur Segmentierung digitalisierter
Keilschrifttafeln in 3D
Evolution regulärer Ausdrücke zur Segmentierung digitalisierter
Keilschrifttafeln in 3D
Ziel der Arbeit ist die Segmentierung dreiecksvernetzter Punktwolken digitalisierter Keilschrifttafeln zur Detektion von Oberflächen und Bruchstellen. Hierzu sollen in der Punktwolke Flächenmerkmale mit dem Blowing-Bubble-Algorithmus bestimmt und anhand von regulären Ausdrücken klassifiziert werden, die mit evolutionären Algorithmen entwickelt werden. Die Applikation und Ergebnisse sind in geeigneter Weise zu evaluieren.
Kolloqium: 19.09.2014
Betreuer: Prof. Dr. Friedhelm Mündemann, Dipl.-Inform. Ingo Boersch
 Systematic Review zum Data Mining zur Prognose von Punktdurchmessern beim Widerstandspunktschweißen
Systematic Review zum Data Mining zur Prognose von Punktdurchmessern beim Widerstandspunktschweißen
Ziel der Arbeit ist eine systematische Übersichtsarbeit zum Stand der Forschung zum Thema Data Mining zur Prognose von Punktdurchmessern von Schweißpunkten beim Widerstandspunktschweißen, insbesondere anhand von Verlaufsgrößen. Hierzu sind die relevanten Forschungsergebnisse möglichst vollständig zu identifizieren, darzustellen, zu beurteilen und zusammenzufassen.
Die Bestimmung relevanter Veröffentlichungen soll systematisch nach einer dokumentierten Methodik erfolgen. Hierzu sind geeignete Suchstrings, Datenquellen, Vorgehensweisen und Kriterien zur Auswahl und Relevanz von Publikationen zu definieren. Die ausgewählten Publikationen sind tabellarisch zusammenzufassen und inhaltlich einzeln kurz vorzustellen. Hierbei sollte sich an vorher formulierten Fragestellungen orientiert werden, wie bspw. Merkmalsdefinition, Modellart, Evaluationsmethode, Prognosegüte oder Datenbasis, die zur Weiterführung des FHB-Projektes sinnvoll sind
Kolloqium: 15.09.2014
Betreuer: Dipl.-Inform. Ingo Boersch, Dipl. Ing. Christoph Großmann (Technische Universität Dresden)
Download: A1-Poster



Unter dem Motto „Big is beautiful“ trafen sich am 27./28.März 2014 Studierende, Lehrende und Vertreter aus der Wirtschaft am HPI in Potsdam zu der Nachwuchsveranstaltung der GI "Informatiktage 2014". Das eingereichte Paper der Masterstudierenden im Data Mining-Projekt wurde angenommen:
Abstract: Beim Widerstandsschweißen spielt der richtige Zeitpunkt des Elektrodenwechsels eine entscheidende Rolle für die Festigkeit der Verbindung und den Ressourcenverbrauch. Wegen einer latenten Verbindungsbildung kann der dafür wichtige Punktdurchmesser aber nicht direkt während des Schweißvorganges gemessen werden. Durch die Vorhersage der Schweißlinse bzw. des Punktdurchmessers mittels eines Prognosemodells könnte die Standmenge optimiert werden. Diese Arbeit beschreibt die Merkmalsextraktion, Merkmalsselektion und Modellerstellung an einer realen Datenmenge. Das finale Modell kann den Linsendurchmesser eines Schweißpunktes zerstörungsfrei in mehr als 92% der Fälle korrekt vorhersagen.
Betreuer der Arbeit: Dipl.-Ing. Christoph Großmann, Dipl.-Inform. Ingo Boersch
Vögel können eine wichtige Rolle im Leben und Kultur der Menschen darstellen. Selbst in Großstädten kann man sie hören und fast jeder erkennt besonders markante Vögel an ihrer Singstimme. Für einige Menschen, wie zum Beispiel Musiker, können ihre Lieder eine Quelle der Inspiration sein. Doch Vögel singen nicht nur aus Vergnügen. [CS95] schrieb, dass Geräusche nur produziert werden, wenn sie auch benötigt werden und damit hat jedes Geräusch eine Bedeutung.
So nutzen also Vögel oder Tiere im Allgemeinen ihre Stimme zur Kommunikation untereinander. Für biologische Forschungen und der Umweltüberwachung ist die Identifizierung von Tieren sehr bedeutsam. Insbesondere bei der Lokalisierung kann sie eine große Rolle spielen, schließlich werden Tiere oftmals zuerst gehört, bevor sie gesehen werden[KM98, LLH06]. Flugzeugunternehmen setzen bereits Systeme zur Vogellokalisierung ein, um Kollisionen zu vermeiden[CM06]. Es gibt also eine Vielzahl von sinnvollen Einsatzgebieten. Eine Menge Wissenschaftler, Umweltaktivisten und Biologen sind an der automatischen Klassifizierung interessiert. Darüber hinaus müssen oftmals Experten eingesetzt werden, um Vogelarten zu identifizieren. Durch Klassifizierungssysteme könnten Ornithologen entlastet werden und effizienter arbeiten.
An der FH Brandenburg wird geplant, bei der Buga 2014, eine Applikation zur Echtzeiterkennung von Vogelarten zu entwickeln und einzusetzen.
Download: Studienarbeit
 Improving Local Navigation by Application of Scan Matching
Techniques in Mobile Robotics
Improving Local Navigation by Application of Scan Matching
Techniques in Mobile Robotics
Ziel der Arbeit ist die Untersuchung verschiedener Registrierungsalgorithmen in Bezug auf die Navigation eines mobilen Roboters vom Typ KUKA. Hierzu sind geeignete Testszenarien zu definieren sowie Versuche zu planen. Anhand selbst gewählter Kriterien sind die Algorithmen zu bewerten und ein begründeter Umsetzungsvorschlag abzugeben. Der Roboter kann simuliert werden. Es werden die Auswirkungen von Scan-Matching-Techniken auf die lokale Navigation eines KUKA omniRob untersucht. Eine Verbesserung der Navigation soll vor allem vor und in vom Roboter befahrenen engen Bereichen angestrebt werden. Bisher korrigierte der Roboter seine Position aufgrund fehlender Genauigkeit sehr häufig vor engen Stellen. Weiterhin soll eine Änderung an der Navigationskomponente in Situationen nach angewandtem Scan-Matching für eine optimierte Fahrt sorgen. Da der reale omniRob noch nicht mit allen Implementierungen verfügbar ist, wird durchgehend in einer Simulation gearbeitet.
Kolloqium: 18.10.2013
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Jochen Heinsohn • Fachhochschule Brandenburg • Dipl.-Math. Christian Rink M. Sc., Dipl.-Math. techn. Daniel Seth • Institut für Robotik und Mechatronik des Deutschen Zentrums für Luft- und Raumfahrt
Download: A1-Poster, Abschlussarbeit
 Definition und Implementierung einer CTS2-standardisierten Abbildung
von Terminologien aus dem Bereich des Infektionsschutzes
Definition und Implementierung einer CTS2-standardisierten Abbildung
von Terminologien aus dem Bereich des Infektionsschutzes
Ziel der Arbeit ist die Abbildung eines Begriffssystems des Robert-Koch-Institutes aus dem Bereich des Infektionsschutzes in das vom Fraunhofer FOKUS entwickelte System CTS2-Le (RDFS-Ontologie) gemäß CTS2-Standards von OMG und HL7. Die Abbildung ist in geeigneter Weise zu evaluieren. Die Eignung der Abbildung zur Wissensrepräsentation ist durch die Implementierung eines einfachen Terminologie-Laders und eine erfolgreiche Kompetenzprüfung anhand geeignet formulierter Kompetenzfragen nachzuweisen.
Kolloqium: 19.09.2013
Betreuer: Dipl.-Inform. Ingo Boersch, Dr.-Ing. Andreas Billig (Fraunhofer FOKUS, Kompetenzzentrum E-HEALTH)
Download: A1-Poster, Abschlussarbeit
 Automatische und assistierende Personaleinsatzplanung basierend auf CSP
Automatische und assistierende Personaleinsatzplanung basierend auf CSP
Das vorliegende Problem der Personaleinsatzplanung ist ein Zuordnungsproblem und gehört der Klasse NP-schwer an. Im Allgemeinen sind solche Probleme nicht in praktisch angemessener Zeit lösbar. Mit problemspezifischen Suchalgorithmen können diese Probleme dennoch auf aktueller Rechentechnik gelöst werden.
Diese Masterarbeit hat das Ziel, das Problem der Personaleinsatzplanung des Unternehmen Coffee Corner zu lösen. Hierbei geht es um die Zuordnung von Mitarbeitern M zu Arbeitsstationen A zu bestimmten Zeiteinheiten Z, wobei M, A und Z Mengen darstellen. Es müssen demnach |A| · |Z| Variablen belegt werden, welche jeweils |M| Werte annehmen können. Der aufgespannte Suchraum umfasst |M||A|·|Z| Zuordnungsmöglichkeiten und somit 10 hoch 875 potenzielle Lösungen. Doch nicht jede Zuordnungsmöglichkeit ist eine gültige Lösung. Ob eine Zuordnungsmöglichkeit eine gültige Lösung ist, wird durch die Einhaltung von Nebenbedingungen entschieden. Ein Ausprobieren aller Möglichkeiten mit Prüfung auf Einhaltung der Nebenbedingungen ist bei steigender Anzahl von Arbeitsstationen, Mitarbeitern und Zeiteinheiten zeitlich zu aufwändig.
Ziel der Arbeit ist eine Untersuchung der Constraint-Propagierung zur Lösung von Personaleinsatzproblemen und die prototypische Umsetzung. Die Evaluation umfasst die Definition geeigneter Kriterien zur Wertung von Plänen, Auswahl von Constraintoptimierungs-Bibliotheken, Heuristiken zur Reduktion des Suchraumes sowie die Integration von Planung und Neuplanung anhand eines realen Anwendungsfalles in der Stadt Brandenburg.
Kolloqium: 30.08.2013
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Michael Syrjakow
Download: A1-Poster
 Vier Studenten des Masterprojektes Data Mining nahmen am
diesjährigen Data Mining
Cup teil und erreichten den Platz 22 von 66 eingereichten
Lösungen.
Vier Studenten des Masterprojektes Data Mining nahmen am
diesjährigen Data Mining
Cup teil und erreichten den Platz 22 von 66 eingereichten
Lösungen.
Folgendes Szenario sollte modelliert werden: Ein Webshop beobachtet seine Besucher (überwiegend Frauen), während sie sich auf der Webseite bewegen. Es soll die Frage beantwortet werden, ob der Besucher seinen Warenkorb letztendlich bestellt oder nicht. Die Trainingsdaten umfassen 50.000 Sessions mit Kundendaten (Alter, Adresscode, Zahlungsanzahl, Acountlebensdauer, Datum der letzten Bestellung, Score, ...) und Sessiondaten (Dauer der Session, Preisverlauf angesehener Artikel, Preise in den Warenkorb gelegter Artikel, Zustandsverlauf im Bestellprozess, ...). Die Klasse ist dann "Session endet mit Bestellung" oder "Session endet ohne Bestellung". Hintergrund der Aufgabe ist das gewünschte automatische Anbieten von Rabatten oder Upselling-Möglichkeiten während einer Session.
Das Team legte im Data Mining-Prozess besonderen Wert auf die zuverlässige Schätzung des zu erwartenden Generalisierungsfehlers, dessen Größenordnung durch die endgültigen Fehlerwerte bestätigt wurde. Es gelang dem Team 93.8% der unbekannten Kundensessions richtig zu klassifizieren (zum Vergleich erreichte das Gewinnerteam der Uni Dortmund eine Erfolgsrate von 97.2%). Eine Übersicht aller teilnehmenden Teams im nebenstehenden Poster.
Es ist also mit Data Mining möglich, das Nutzerverhalten in diesem Szenario sicher vorherzusagen, wahrscheinlich sogar, bevor dem Nutzer selbst seine Entscheidung bewusst wird.
 Automatisierte Merkmalsextraktion und Klassifizierung von
Vogelstimmen mittels genetischer Programmierung
Automatisierte Merkmalsextraktion und Klassifizierung von
Vogelstimmen mittels genetischer Programmierung
Ziel der Arbeit ist die Evaluation einer Methode zur automatischen Merkmalsextraktion mit Genetischem Programmieren. auf diesem Wege sollen Merkmale definiert werden, die sich zur Klassifikation von Vogelstimmen eignen. So erzeugte Merkmale können zum Einen genutzt werden, um von Ornithologen erstellte Langzeitaufnahmen zu bearbeiten oder für Hobby-Ornithologen, um mit einer Smartphone-Applikation Vögel aufzunehmen und zuzuordnen.
In der Arbeit soll aufbauend auf Arbeiten an der Universität Dortmund von Ingo Mierswa und Katharina Morik die prinzipielle Eignung des Ansatzes untersucht und anhand einer praktischen Umsetzung bewertet werden. Schwerpunkt sei hierbei die erfolgreiche und weiterverwendbare Umsetzung des Evolutionszyklus im GP-Framework ECJ.
Kolloqium: 28.06.2013
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Michael Syrjakow
Download: A1-Poster
|
Data Mining – 1. Studentischer
Workshop
28.05.2013, FH Brandenburg,
Informatikzentrum, R 131, 9:30 Uhr
|
Wir laden alle Interessierten zu einem zwanglosen Austausch zu Werkzeugen, Vorgehensweisen und Aufgabenstellungen im Bereich der Datenanalyse ein.

Widerstandspunktschweißen ist das im Stahl-Karosseriebau am häufigsten verwendete Fügeverfahren. Dabei spielt der richtige Zeitpunkt des Elektrodenwechsels eine kritische Rolle. Um haltbare Schweißpunkte zu garantieren, werden die Elektroden anhand pessimistischer, empirisch bestimmter Heuristiken in der Praxis sehr früh gewechselt. Insbesondere beim Schweißen hochfester beschichteter Bleche mit hohen Strömen erreichen die Heuristiken ihre Grenzen. Könnte die Standzeit der Elektroden anhand eines Prognosemodells optimiert werden, sind jährliche volkswirtschaftliche Einsparungen an den Elektroden-Rohstoffen (überwiegend Kupfer) in Millionenhöhe zu erwarten.
Die Arbeitsgruppe Thermisches Fügen der TU Dresden untersucht die Verschleißmechanismen der Elektrodenkappen mit dem Ziel neue zerstörungsfreie Prüfverfahren für das Widerstandspunktschweißen zu entwickeln. In Kooperation mit dem Masterprojekt Data Mining der FH Brandenburg erfolgt eine Untersuchung, mit welcher Güte sich der für die Stabilität eines Schweißpunktes relevante Punktdurchmesser aus Verlaufsgrößen des Schweißvorganges bestimmen lässt. Die besondere Schwierigkeit der Data Mining-Aufgabe besteht in der Definition geeigneter Merkmale aus Wertereihen und der Schätzung der Modellgüte bei dem vorliegenden geringen Umfang der klassifizierten Stichprobe. Der Prozess selbst ist nach Ansicht der Technologen schwierig zu modellieren, da beim Schweißen hochfester Stähle mit hohen Stromstärken Spritzer flüssigen Materials auftreten können.
Die Rohdaten wurden im Schweißlabor der TU Dresden experimentell erhoben und liegen pro Schweißvorgang in Form multivariater Zeitreihen als TDMS-File vor. Hierzu wurden mit sechs Elektroden je 2000 Schweißpunkte geschweißt und dabei 10 Prozessgrößen (sog. Kanäle), wie bspw. Spannung, im Kilohertz-Bereich aufgezeichnet. An 400 Schweißpunkten dieser Stichprobe wurde die Zielgröße Punktdurchmesser manuell bestimmt. Die Daten sind nicht öffentlich.
Die Daten enthielten fehlende Werte, Triggerfehler, Ausreißer, Fehlmessungen sowie Störungen durch nicht erfasste Einflussgrößen, wie parallele Nutzung von Kühlkreisläufen durch andere Projekte. Die explorative Analyse half Datenfehler aufzudecken und zeigte deutlich die Prozessphasen des Schweißprozesses, führte jedoch zu keinen offensichtlichen Merkmalen.
Zur Merkmalsdefinition wurden die Prozessgrößenmit einer parameterfreien Methode [Wit83] kanalweise segmentiert und segmentweise deskriptive statistische Merkmale berechnet. Zusätzlich wurden neue Kanäle durch Verknüpfung bestehender Kanäle erzeugt [AH12]. Aus der damit definierten Menge von mehr als 1000 Merkmalen wurde anhand von klassenbasierten Filtermethoden eine geeignete Untermenge relevanter Merkmalen bestimmt. Bei der Evaluation linearer Modelle [Fah09] und Modellbäumen erwiesen sich Modellbäume [Qui92] als bessere und zudem transparente Wissensrepräsentation [MM12].
Als Erfolg wurde eine Prognose des Punktdurchmessers in einem 10%-Intervall um den echten Wert definiert (Erfolgsrate) und zur Modellauswahl der mittlere quadratische Fehler verwendet. Die Datenmenge wurde im Holdout-Verfahren disjunkt in 90% Trainings- und 10% Testdaten geteilt. Die Modellauswahl erfolgte auf den Trainingsdaten mit 10-facher Kreuzvalidierung. Die Analyseskripte und Zwischendatenmengen wurden versioniert, somit sind alle Ergebnisse mit den Originaldaten reproduzierbar.
Der gewählte Ansatz konnte den echten Punktdurchmesser in 75% der Testfälle im 10%-Intervall korrekt vorhersagen. Dies ist unter Berücksichtigung der technologischen Schwierigkeiten ein gutes Ergebnis. Das finale Modell ist menschenlesbar und seine Plausibilität kann mit den Prozessexperten diskutiert werden. Die Datenverarbeitungswerkzeuge wurden entwickelt und können für ähnliche Analysen verwendet und erweitert werden. Ein nächstes Projekt wird das Analyse-Verfahren auf einen technologisch einfacheren Schweißprozess anwenden und um strukturbasierte Merkmale erweitern.
[AH12] Benjamin Arndt and Benjamin Hoffmann. Segmentierung und Merkmalsdefinition mehrkanaliger Messdaten zur Prognose bei einem punktförmigen Fügeverfahren. In 14. Nachwuchswissenschaftlerkonferenz, Brandenburg, 18.04.2013.
[Fah09] Fahrmeir, L., Künstler, R., Pigeot, I. and Tutz, G. (2009, 5., verb. Aufl.). Statistik - Der Weg zur Datenanalyse. Springer Verlag, 2009
[MM12] Curtis Mosters and Josef Mögelin. Merkmalsselektion und transparente Modellierung zur Prognose einer Zielgröße bei einem punktförmigen Fügeverfahren. In 14. Nachwuchswissenschaftlerkonferenz, Brandenburg, 18.04.2013.
[Qui92] Ross J. Quinlan. Learning with Continuous Classes. In: 5th Australian Joint Conference on Artificial Intelligence, pages 343–348. Singapore, 1992.
[Wit83] Andrew P. Witkin. Scale-space filtering. In Proceedings of the Eighth international joint conference on Artificial intelligence - Volume 2, IJCAI’83, pages 1019–1022, San Francisco, CA, USA, 1983. Morgan Kaufmann Publishers Inc.
Abb 1: Das vorsichtige Öffnen eines Schweißpunktes ist aufwändig, aber zur korrekten Vermessung des Punktdurchmessers notwendig
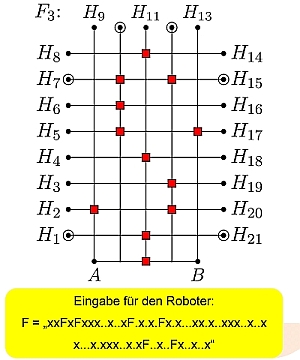 PRT
- Personal Rapid Transit
PRT
- Personal Rapid Transit
Ein PRT-System ist eine Flotte kleiner Fahrzeuge, die jeweils eine oder
wenige Personen ohne Zwischenhalt zu individuellen Zielen
transportieren. Das derzeit größte geplante PRT-Netz mit 30.000
3000 Fahrzeugen entsteht in Masdar City, einer am Reißbrett entworfenen
Stadt in der Wüste der Vereinigten Arabischen Emirate. In Masdar City
sollen 50.000 Menschen CO2- und energieneutral leben und arbeiten.
Fahrzeuge mit Verbrennungsmotoren wird es dort nicht geben. Eine erste
Testinstallation eines PRT-Netzes der Firma 2getthere (Niederlande) mit
10 Fahrzeugen, zwei Personen- und drei Frachtstationen ist seit August
2011 in Masdar City in Betrieb.
Probleme im PRT-Netz entstehen bei Überlastung (globaler Stau) oder durch liegenbleibende Fahrzeuge. Der damit verbundene Verlust befahrbarer Strecken erfordert ein Neuplanen von Fahrtrouten. Und hier kommen Sie ins Spiel.
Aufgabe
Ihr Roboter erhält den Auftrag, eine oder mehrere Personen abzuholen und zum Ziel zu bringen. Das Streckennetz ist ein einfaches Gitter, in dem es allerdings zu Störungen und damit unbefahrbaren Kreuzungen kommen kann. Die gute Nachricht ist, das Sie über globales Wissen verfügen und die aktuelle Karte der befahrbaren Wege dem Roboter kurz vor dem Start zur Verfügung gestellt wird.
Es ist eine der schwierigsten Aufgaben der letzten Jahre in diesem Projekt, da zusätzlich zur Roboterkonstruktion und -programmierung auch die Breitensuche eines optimalen Pfades zwar nach Lehrbuch aber mit vielen Detailproblemen zu lösen ist. Diesmal existiert keine Minimallösung (eingängig, wiederholbar, einfach zu bauen [BHL98]) - entweder ALLE Komponenten erfüllen ihre Aufgabe oder das System scheitert. Der Umfang der zu lösenden Teilprobleme erfordert eine klare Arbeitsteilung im Projekt, 10 Studenten in vier Teams nahmen teil.
Folgende Roboter traten an, verlinkt sind die Projektberichte:

 Unter dem Motto „innovativ und exzellent“ zeichnete die Fachhochschule
Brandenburg am 7. Dezember Nachwuchswissenschaftler mit dem
Innovationspreis 2012 aus. Der Preis wird für herausragende, an
betrieblichen Bedürfnissen orientierte Innovationen vergeben und von
Unternehmen der Region gestiftet.
Unter dem Motto „innovativ und exzellent“ zeichnete die Fachhochschule
Brandenburg am 7. Dezember Nachwuchswissenschaftler mit dem
Innovationspreis 2012 aus. Der Preis wird für herausragende, an
betrieblichen Bedürfnissen orientierte Innovationen vergeben und von
Unternehmen der Region gestiftet.
Platz drei des Innovationspreises wurde in diesem Jahr an David Walter vergeben, der in seiner Masterarbeit erfolgreich ein Verfahren zur Prognose des Stromverbrauches für die Stadtwerke Brandenburg an der Havel GmbH entwickelte.
 Entwicklung und Evaluation eines multimodalen Empfehlungssystems für
Lokationen
Entwicklung und Evaluation eines multimodalen Empfehlungssystems für
Lokationen
In den vergangenen Jahren haben multimodale Anwendungen den Schritt von der Forschung in die Praxis gemacht. Ziel der Kombination verschiedener Modalitäten wie Sprache und Touch (Berührung) ist es, eine bessere und natürlichere Interaktion zwischen Benutzer und System zu ermöglichen.
In dieser Arbeit wurde ein leichtgewichtiges, multimodales, karten-basiertes Empfehlungssystem für das Auffinden von Lokationen zur Erfüllung von Aufgaben entwickelt. Existierende Dienste und Komponenten – wie zum Beispiel zur Georeferenzierung oder zur Spracherkennung – wurden erfolgreich zu einem funktionierenden System kombiniert. Der Einsatz von Webtechnologien wie HTML, CSS und JavaScript vereinfacht die Portierung der mobilen Android-App auf andere Plattformen. Eine in JavaScript definierte Grammatik erlaubt verschiedene Varianten bei der Spracheingabe.
Im Anschluss an die Entwicklung wurde eine Evaluation des Systems mit zwölf Versuchsteilnehmern vorgenommen. Diese beinhaltete neben dem Lösen von jeweils sechs Aufgaben die Beantwortung zweier Fragebögen. Es wurde insbesondere untersucht, ob Daten sozialer Netzwerke den Benutzer bei der Auswahl von Lokationen unterstützen können (H1) und ob Sprache die Eingabe erleichtert (H2). Die Befragung zeigt, dass 11 von 12 Personen der Meinung sind, dass soziale Netzwerke bei der Entscheidungsfindung helfen. Zehn der 12 Probanden bevorzugten die (initiale) Eingabe via Sprache. Nach dem Lösen der Aufgaben verbesserte sich die Bewertung der Nützlichkeit von Spracheingabe bei fünf Personen – nur eine Person änderte ihre Einschätzung zum Negativen. Beide Hypothesen ließen sich somit bestätigen.
Kolloquium: 02.10.2012
Betreuer: Prof. Dr. Jochen Heinsohn, Dipl.-Inform. Ingo Boersch, Dr. Tatjana Scheffler (DFKI), Dipl.-Inf. Rafael Schirru (DFKI)
Download: A1-Poster, Abschlussarbeit
 Repräsentation medizinischen Wissens mit Drools am Beispiel der
Adipositas-Leitlinie
Repräsentation medizinischen Wissens mit Drools am Beispiel der
Adipositas-Leitlinie
Ziel der Arbeit ist die Untersuchung, inwieweit sich die Rule Engine Drools zur Repräsentation und Verarbeitung medizinischen Regelwissens eignet. Dazu soll die Leitlinie zur Prävention und Therapie von Adipositas prototypisch in einem wissensbasierten System modelliert werden. Des Weiteren soll ein Benutzerhandbuch für Droolseinsteiger entstehen.
Praktisches Ergebis der Arbeit sei ein prototypisches wissensbasiertes System zum Laden und Verarbeiten (Vorwärtsverkettung) einer Regel- und Faktenbasis (Patientendaten) zur Adipositas-Therapie.
Kolloquium: 02.10.2012
Betreuer: Prof. Dr. Jochen Heinsohn, Dipl.-Inform. Ingo Boersch
Download: A1-Poster, Abschlussarbeit, Programm, Quelltext, Wissensbasis (zip, 11MB)
Zum Start des Programmes die ZIP-Datei auspacken und das Programm mit einem Doppelklick auf 'Quellcode\DroolsGui\DroolsGUI.jar' starten. Im Programm zunächst die vier Bestandteile der Wissensbasis (dataModel.drl, diagnose_rules.drl, testPatienten.drl und therapie_rules.drl) im Verzeichnis 'Quellcode\Drools Rule Files' laden, die Wissensbasis kompilieren und zum Schluss die Vorwärtsverkettung starten.
Für eigene Versuche können die DRL-Files (Wissensbasis als Textdatei) mit einem beliebigen Editor verändert oder eigene DRL-Files verwendet werden.
 Entwurf und Implementierung von Suchverfahren am Beispiel des Spiels “Rush-Hour” mit Visualisierung der Lösungsfindung
Entwurf und Implementierung von Suchverfahren am Beispiel des Spiels “Rush-Hour” mit Visualisierung der Lösungsfindung
Ziel der Bachelorarbeit ist die Entwicklung einer Applikation zur Visualisierung einfacher Suchalgorithmen am Beispiel des Rushhour-Problems.
Insbesondere soll das Laden verschiedener Problemkonfigurationen der Rush-Hour-Domäne in einer geeigneten textuellen Repräsentation, das Finden einer oder aller Lösungen sowie das Verfolgen der Arbeitsweise der Suchalgorithmen (Tiefensuche, Breitensuche, A*) ermöglicht werden. Der Zustandsraum der Suchprobleme soll in geeigneten Metriken (bspw. Anzahl der Knoten, Anzahl der Lösungen) dargestellt werden.
Kolloquium: 27.09.2012
Betreuer: Prof. Dr. rer. nat. Rolf Socher, Dipl.-Inform. Ingo Boersch
Download: A1-Poster
 Modellierung der Studien- und Prüfungsordnung des Studiengangs
Bachelor Informatik in OWL
Modellierung der Studien- und Prüfungsordnung des Studiengangs
Bachelor Informatik in OWL
Ziel der Bachelorarbeit ist die ontologische Modellierung der Studien- und Prüfungsordnung der Informatik.
Die Ordnung soll in maschinenverständlicher Form, d.h. zugänglich für Visualisierung, Navigation, Abfragen und Inferenzen im Sinne des Semantic Web repräsentiert werden. Das konkrete Ziel ist eine Ontologie, die zu bestimmten Themen des Studiums befragt werden kann. Sie soll alle Fragen beantworten, die auch mit der originalen Ordnung beantwortet werden. Zudem sollten Schlüsse gezogen werden können, die weiteres Wissen generieren. Fragen könnten sein:"Was sind Pflichtfächer?", "Muss ich ein Praktikum machen?", "Wie lang ist die Bearbeitungszeit für eine Bachelorarbeit?".
Die Ontologie soll sich auf andere (ähnliche) Prüfungs- und Studienordnungen erweitern lassen.
Kolloquium: 18.09.2012
Betreuer: Prof. Dr. Jochen Heinsohn, Dipl.-Inform. Ingo Boersch
Download: A1-Poster
 Interaktive Evolution zur Assistenz bei der Einrichtungsplanung
Interaktive Evolution zur Assistenz bei der Einrichtungsplanung
Die Planung der Inneneinrichtung von Räumen ist oft aufwändig und zeitintensiv, da ein weites Spektrum verschiedenster Einrichtungsgegenstände verfügbar ist und diese fast beliebig kombiniert werden können. Diese Arbeit schlägt interaktive evolutionäre Algorithmen zur Assistenz bei der Einrichtungsplanung vor. Dazu werden zunächst die Bestandteile der interaktiven Evolution genauer definiert und Arten der interaktiven Selektion vorgestellt. Anschließend wird die Konzeption und Entwicklung des Softwaresystems dokumentiert.
Zur Verringerung der Benutzerermüdung wird die Methode der Sparse Fitness Evaluation umgesetzt. Es werden Versuche mit der entwickelten Software durchgeführt und aufgetretene Probleme diskutiert. Abschließend gibt die Arbeit einen Ausblick für eine weitere Entwicklung.
Kolloqium: 29.08.2012
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Michael Syrjakow
Download: A1-Poster, Masterarbeit, Quelltexte (85MB)
Software: Furny-1.0.zip in ein beliebiges Verzeichnis entpacken, in dieses Verzeichnis wechseln und den gewünschten Teil mit den .bat-Dateien starten
 Agent Sairo (ein Programm zur Steuerung des autonomen Segelbootes) tritt
gegen Jochen Heinsohn in einem Up-and-down-Kurs auf dem Beetzsee an. Die Navigationsaufgabe
entspricht einer Einzelaufgabe beim WRSC und besteht aus dem Überqueren
einer 3m-breiten Startlinie, Fahrt gegen den Wind um eine Boje gegen die
Uhrzeigerrichtung und Rückkehr über die Startlinie
Agent Sairo (ein Programm zur Steuerung des autonomen Segelbootes) tritt
gegen Jochen Heinsohn in einem Up-and-down-Kurs auf dem Beetzsee an. Die Navigationsaufgabe
entspricht einer Einzelaufgabe beim WRSC und besteht aus dem Überqueren
einer 3m-breiten Startlinie, Fahrt gegen den Wind um eine Boje gegen die
Uhrzeigerrichtung und Rückkehr über die Startlinie
“The objective of the navigation contest is to evaluate a
boat’s ability to accurately navigate a short upwind‐downwind course,
all without manual between two red marks sailing windward to a mark in
approximately 20‐60 m distance. After rounding the mark on port, the
boat shall sail between the red marks again.”
[Sailing
instructions, World Robotic Sailing Championship / International Robotic
Sailing Conference 2011, Universität zu Lübeck]
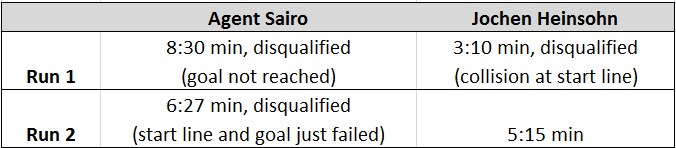
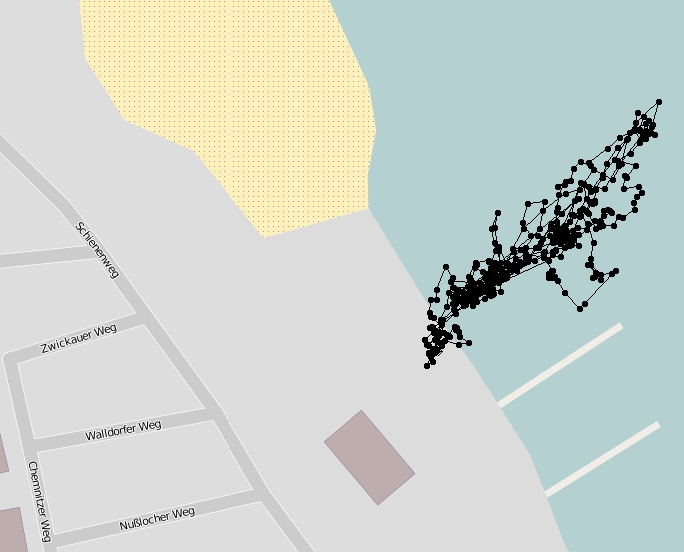
 Analyse und Optimierung der Prognosegüte des Strombedarfs als Grundlage
der Querverbundsoptimierung der Stadtwerke Brandenburg
Analyse und Optimierung der Prognosegüte des Strombedarfs als Grundlage
der Querverbundsoptimierung der Stadtwerke Brandenburg
Es gilt das vorhandene proprietäre Softwaresystem zur Ressourcenplanung und Erstellung von Bedarfsprognosen zu untersuchen. Dabei soll in der Datenanalyse die Güte der bisherigen Prognosen analysiert werden und der Zusammenhang zwischen dem Strombedarf im Netzgebiet und den messbaren exogenen Größen untersucht werden. Um die Prognosegüte zu verbessern, werden verschiedene Methoden zur Lastprognose evaluiert, das vorhandene System auf Optimierungsmöglichkeiten untersucht und ein Prognoseverfahren implementiert.
Neben der Implementierung von JForecast wurden Prognosemodelle aus dem vorhandenen Softwaresystem mit verschiedenen Parametersetups evaluiert und mit einem Testszenario die Ergebnisse verglichen.
Kolloquium: 01.06.2012
Betreuer: Prof. Dr.-Ing. Jochen Heinsohn, Dr. Tino Schonert (Stadtwerke Brandenburg an der Havel GmbH), Dipl.-Inform. Ingo Boersch
Download: A1-Poster
Ende April scheint der Segelroboter mit der neuen Architektur bereit für die erste Mission: autonome Fahrt zu einem Zielpunkt - ohne Segel mit Motor. Ideale Bedingungen bot hierzu das Gelände des Märkischen Seglervereins Brandenburg nahe der Regattastrecke, bspw. ein Ruderboot und Steg. Wetterbedingungen: leicht bewölkt, trocken, 16°C, Windstärke 0-1.

Folgendes sollte getestet werden:
1. Handlebarkeit:
2. Generelle Anforderungen:
3. Funktionalität Fernsteuerung:
4. Funktionalität WLAN:
5. Programm manueller Modus (Fernbedienung + VNC):
6. Programm autonomer Modus:
7. Missionen
8. Laufzeiten der Akkus protokollieren: Boot, Bootsrechner, Ufer-PC
Beim Meilenstein ergab sich eine lange Liste von neuen Aufgaben und insbesondere war der Motor durch den BootsPC nicht mit einer ausreichenden Geschwindigkeit ansteuerbar, so dass der Missionskern des Meilensteins nicht voll erreicht wurde. In zwei Wochen auf ein Neues.
 Entwicklung und Evaluierung von Clustering-Verfahren für Points of
Interest verschiedener thematischer Kategorien
Entwicklung und Evaluierung von Clustering-Verfahren für Points of
Interest verschiedener thematischer Kategorien
In dieser Arbeit geht es um die Entwicklung einer Anwendung zur Darstellung von konzentrierten Gebieten von Points of Interest (PoIs). Dadurch soll einem Anwender z. B. ein Ballungsgebiet von Restaurants innerhalb des urbanen Umfelds angezeigt werden.
Der Vorgang, Wertemengen nach ihrer Ähnlichkeit (hier nach geographischer Distanz) zu gruppieren, ist eine Disziplin des Data Minings und wird als Cluster-Analyse bezeichnet. Verschiedene Clustering-Verfahren sollen getestet und angepasst werden, um ihre Eignung für die Aufgabenstellung zu bewerten und zu optimieren.
Evaluiert wurden das Minimum spanning tree Clustering, k-Means, sowie ein selbstentwickeltes DK-Means-Verfahren.
Kolloquium: 10.02.2012
Betreuer: Dipl.-Inform. Ingo Boersch, Dr. Inessa Seifert (DFKI)
Download: A1-Poster
 Analyse von Matching-Verfahren und Konzeption für eine auf Angebot und
Nachfrage basierende Plattform – Prototypische Implementierung am
Beispiel einer Lehrstellenbörse
Analyse von Matching-Verfahren und Konzeption für eine auf Angebot und
Nachfrage basierende Plattform – Prototypische Implementierung am
Beispiel einer Lehrstellenbörse
In dieser Arbeit wird das als Matching bezeichnete Zuordnungsproblem zwischen Nachfrage generierenden Benutzern und Angebot repräsentierenden Objekten untersucht. Ziel ist eine automatische, individuelle Auswahl von geeigneten Objekten für den einzelnen Nutzer, die seinen Präferenzen entsprechen. Beschränkt wird diese Problematik auf webbasierte Plattformen, wobei die registrierten Benutzer durch Nutzerprofile beschrieben werden und die Angebote als Objekte angesehen werden, deren Eignung für die einzelnen Nutzer bestimmt werden soll.
Zur Lösung dieses Problems stehen verschiedene Ansätze zur Verfügung. Empfehlungssysteme erstellen Vorschläge basierend auf vorhandenen Bewertungen des Nutzers für Objekte. Die Clusteranalyse gruppiert die Objekte zu Clustern, die eine möglichst homogene Menge an Objekten beinhalten. Eine hohe Eignung wird Objekten aus Clustern unterstellt, aus denen bisher positiv bewertete Objekte stammen. Klassifizierungs- und Regressionsverfahren berechnen eine Klassenzuordnung bzw. eine numerische Prognose, die Aussagen über die Eignung eines Objekts treffen.
Die Verfahren werden hinsichtlich ihrer Eignung für das beschriebene Problem evaluiert. Auf Basis dieser Untersuchung wird ein Konzept für das Anwendungsbeispiel einer Lehrstellenbörse entwickelt und prototypisch implementiert.
Kolloquium: 28.09.2011
Betreuer: Dipl.-Inform. Ingo Boersch, Dipl.-Inform. Dirk Wieczorek (]init[)
Download: A1-Poster
 Matching und Visualisierung von Points of Interest aus sozialen Daten
Matching und Visualisierung von Points of Interest aus sozialen Daten
Ziel der Bachelorarbeit ist eine Untersuchung zu Möglichkeiten der gegenseitigen Abbildung nutzergenerierter interessanter Orte (POI) aus drei sozialen Netzwerken mit Orten aus dem Openstreetmap-Projekt. Die Ansätze sollen prototypisch implementiert und die Matching-Ergebnisse visualisiert und evaluiert werden.
In der Arbeit werden verschiedene Algorithmen oder Kombinationen jener Algorithmen gegenüber gestellt und deren Vor- und Nachteile erörtert. Ferner wird auch darauf eingegangen, welche Fehler bei bestimmten Abläufen auftreten und wodurch sie provoziert werden. Nach dem Matching muss bestimmt werden, wie der resultierende PoI am Ende repräsentiert werden soll, seine kanonische Repräsentation. Die Paare von PoIs sollen dann über einen Webservice verfügbar sein. Zur Veranschaulichung der Ergebnisse werden die PoIs in einer Android-App auf einer Google-Maps-Karte visualisiert, die die Daten von dem Webservice bekommt.
Kolloquium: 21.09.2011
Betreuer: Dipl.-Inform. Ingo Boersch, Dr. Tatjana Scheffler (Deutsches Forschungszentrum für Künstliche Intelligenz GmbH)
Download: A1-Poster, Bachelorarbeit
 Kontext-spezifische Analyse von Benutzerpräferenzen mittels Clustering
für Musikempfehlungen auf Grundlage von Semantic-Web-Metadaten
Kontext-spezifische Analyse von Benutzerpräferenzen mittels Clustering
für Musikempfehlungen auf Grundlage von Semantic-Web-Metadaten
In dieser Masterarbeit wird ein Verfahren vorgestellt, mit dem Benutzerprofile extrahiert werden können, die als Basis für Musikempfehlungen genutzt werden können. Um dieses Ziel zu erreichen werden die Künstler, die ein Nutzer gehört hat, mit Metadaten beschrieben, die im Semantic-Web gefunden werden können.
Nach der Vorverarbeitung der Daten beginnt das Clustering der Künstler. Dadurch werden sie anhand ihres Musikstils in unterschiedliche Cluster unterteilt. Für jedes dieser Cluster wird dann ein Label gewählt, mit dem die zugrunde liegende Musikrichtung beschrieben werden kann. Diese Labels formen dann ein Benutzerprofil, welches ein breites Spektrum des Musikgeschmacks eines Nutzers widerspiegelt.
Durch die Evaluation kann gezeigt werden, dass die extrahierten Benutzerprofile spezifisch für die unterschiedlichen Musikrichtungen der Nutzer sind. Somit können sie als Basis für Empfehlungssysteme dienen, oder in bereits bestehende Anwendungen integriert werden.
Kolloquium: 25.08.2011
Betreuer: Prof. Dr.-Ing. Jochen Heinsohn, Dipl.-Inf. Rafael Schirru (DFKI GmbH), Dipl.-Inform. Ingo Boersch
Download: A1-Poster, Masterarbeit
Das Ziel dieser Arbeit ist, eine Übersicht über Anwendungsfälle, Probleme und Konzepte zur Umsetzung von interaktiven evolutionären Algorithmen zu erstellen. Dabei sollen reale und mögliche Anwendungsszenarien systematisiert werden. Es soll durch eine Literaturrecherche untersucht werden, welche Methoden existieren, um dem Problem der Benutzerermüdung entgegen zu wirken.
Die Methoden sollen in Form einer Taxonomie nach ihren spezifischen Eigenschaften klassifiziert werden. Weiterhin soll untersucht werden, welche Modelle für Benutzerschnittstellen zur interaktiven Fitnessbestimmung existieren. Diese sollen nach ihren Eigenschaften und ihrer Eignung für die parallele Nutzung durch mehrere Benutzer aufgelistet werden. Dazu sollen die speziellen Vorteile und Probleme von Multi-Touch-Systemen untersucht und berücksichtigt werden. Anschließend soll prototypisch eine Software zur Demonstration der Vorteile von Multi-Touch-Systemen entwickelt werden.
Abgabe 28.02.2011
Betreuer: Dipl.-Inform. Ingo Boersch
Download: Studienarbeit
 Recherche und Poster zum Thema "GenePool - Implizite Evolution"
Recherche und Poster zum Thema "GenePool - Implizite Evolution"
Praktikumsarbeit (Gymnasium) von Niklas Schabbel, Timo Boersch und Dennis Schmidt
Download: A1-Poster

Die Arbeit beschäftigt sich mit der Integration von Data-Mining-Methoden, die zur Analyse der Daten aus dem astrophysikalischen Experiment LOPES benutzt werden können. Den Hauptteil der Arbeit bilden die Implementierung und Beschreibung der Software, welche die vorgenannte Integration durchführt. Der erste Teil dieser Beschreibung besteht aus der Analyse der Anforderungen an die Software zusammen mit der notwendigen Theorie der verwendeten Data-Mining-Methoden. Der zweite Teil ist eine Software- Engineering-orientierte Darstellung der implementierten Lösungen. Da die interessierte Leserschaft sowohl aus Informatikern als auch Physikern besteht, beginnt die Arbeit mit der allgemeinen Vorstellung des LOPES-Experiments und den Grundideen des Data Mining.
Kolloquium: 26.08.2010
Betreuer: Prof. Dr. Jochen Heinsohn (FHB), Prof. Dr. Johannes Blümer (Karlsruher Institut für Technologie)
Download: A1-Poster Masterarbeit

Zur Demonstration adaptiver Fähigkeiten evolutionärer Systeme entwarf, konstruierte und programmierte Stephan Dreyer das autonome Systeme GeneFlower, das mit einem genetischen Algorithmus eine Mehrzieloptimierung in Richtung eines hohen Lichteinfalls bei wenig Energieverbrauch löst. Umgesetzt wurde ein steady-state GA mit Turnierselektion, altersabhängiger Ersetzungsselektion, 1-Punkt-Crossover und Integermutation. Programmiert wurde in C für das Mikrocontroller-Board AKSEN.
Der Funktionsnachweis wurde durch Fitnessprotokollierung bei stabiler Umwelt erbracht, aber auch bei dynamischer Umwelt reagiert das System wie erwartet mit einer ständigen Anpassung. Das gilt nicht nur für die Änderung des Lichteinfalls, sondern insbesondere auch bei Änderung der Aktorik durch Motorausfall, mechanische Änderung oder Verwickeln der Zugseile.
Intrinsisches Ziel des Systems ist: "Ich stehe in der Sonne und tue nichts".
Download: 2010-06-06 Stephan Dreyer - GeneFlower.pdf

 Optimierung und Evaluierung einer Routenabgleichkomponente in einer
Ad-Hoc-Mitfahrerzentrale
Optimierung und Evaluierung einer Routenabgleichkomponente in einer
Ad-Hoc-Mitfahrerzentrale
Ziel dieser Arbeit ist das Testen und Überarbeiten eines bestehenden Mitfahrersuchalgorithmus, der vom Fraunhofer Institut für offene Kommunikationssysteme entwickelt wird.
Mit dem Algorithmus werden passende Mitfahrgesuche für einen Fahrer ermittelt, wobei die Lösung bei Kurzstrecken zum Einsatz kommen soll. Es gilt herauszufinden, unter welchen Bedingungen, wie viele Mitfahrer, in welcher Zeit, für den Fahrer gefunden werden. Weiterhin werden alternative Ansätze entwickelt und miteinander verglichen.
Kolloquium: 12.05.2010
Betreuer: Dipl.-Inform. Ingo Boersch, Dipl.-Inform. A. Kress (Fraunhofer Institut für offene Kommunikationssysteme)
Download: A1-Poster
Die retinale Nervenfaserschichtdicke (engl.: retinal nerve fiber layer
thickness, RNFLT) ist ein moderner Parameter in der Augendiagnostik.
Mittels optischer Kohärenztomographie (engl.: optical coherence
tomography, kurz OCT) wird hierbei in einem Augen-Laserscan die
Faserdicke der Augennerven in 256 radialen Einzelmesswerten bestimmt.
Die RNFLT zeigt dabei spezifische Veränderungen in verschiedenen
Krankheitsbildern und hält zunehmend Einzug in die Routinediagnostik.
Im
Rahmen einer Studie sollen Modelle zum Vergleich der RNFLT-Veränderungen
bei Patienten mit unterschiedlichen Erkrankungen gegenüber
Kontrollmessungen bei gesunden Probanden bestimmt werden. Bisherige
Vergleichsmethoden umfassen lediglich die mittlere Abnahme der Messwerte
und berücksichtigen nicht typische Kurvenveränderungen. Im Rahmen dieser
Abschlussarbeit sollen diese Messungen zuerst elektronisch erfasst,
verarbeitet und die Auswertungen online verfügbar gemacht werden. Mit
Hilfe von Kurvenanalyse und dem Einsatz von Methoden des maschinellen
Lernens sollen genauere Lösungen für dieses Klassifikationsproblem
entwickelt werden..
Kolloquium: 25.11.2009
Betreuer: Dipl. Inform. Ingo Boersch, Master of Science Sebastian Mansow-Model (mediber GmbH)
Download: A1-Poster, Diplomarbeit

Das Ziel der Arbeit ist für ein Lager eine Auslagerungs-Strategie umzusetzen bzw. zu modifizieren, sodass die zu fahrende Gesamtroute für eine Auslagerung bestimmter Produkte so kurz wie möglich ist. Die einzige Nebenbedingung ist, dass der Lagerschlitten, also die Einheit, die für das Greifen der Produkte zuständig ist, für eine Tour nur eine bestimmte Anzahl an Produkten aufnehmen kann. Erst nachdem die aufgenommenen Güter dann an einem definierten Ort abgelegt wurden, kann eine weitere Tour gestartet werden. Abbruchbedingung für die Berechnung der Route kann eine bestimmte Zeit sein, welche vorher definiert wird.
Zusätzlich ist es wichtig zu analysieren, wie effektiv bekannte Verfahren sind und ob diese hinsichtlich des speziellen Problems noch optimiert werden können. Ziel der Diplomarbeit ist die Entwicklung und Umsetzung einer Auslagerungsstrategie für eine Lagerverwaltung. Hierbei sollen Aufträge zur Auslagerung von Gütern angenommen, eine kurze Route berechnet und ein reales Lagermodell angesteuert werden. Der theoretische Schwerpunkt liegt hierbei auf der Einordnung des Routingproblems und der Auswahl eines geeigneten Optimierungsverfahrens. Das Verfahren soll in eine funktionsfähige Applikation umgesetzt werden, welche die Planungskomponente als Modul enthält, sowie eine Visualisierung des Planungsprozesses und der erstellten Routen vornimmt. Die Funktionalität und Geschwindigkeit ist durch geeignete Experimente nachzuweisen.
Kolloquium: 02.06.2009
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Michael Syrjakow
Download: A1-Poster, Diplomarbeit

Populärwissenschaftlicher Vortrag in der Hochschulreihe der FH Brandenburg zum Thema Data Mining
Download: Folien

Zielstellung des Themas ist die Untersuchung der Anwendbarkeit von Methoden des Data Mining zum Finden und Modellieren von Abhängigkeiten der an fertigen Solarmodulen gemessenen Größen von den Parametern und Messwerten des Produktionsprozesses. Die auszuwertenden Daten liegen dabei zu Beginn der Arbeit im Wesentlichen als Tabelle vor.
Die Arbeit umfasst in einem ersten Teil die Einordnung der Aufgabenstellung in den wissenschaftlichen Kontext und das Umfeld beim Hersteller, die notwendige Datenvorbereitung (bspw. geeignete Behandlung von fehlenden Werten, Normalisierung, Diskretisierung, Selek-tion und Aggregation von Merkmalen), die Formulierung und Test einfacher Hypothesen (bspw. statistische Abhängigkeit), Darstellung von Werten der deskriptiven Statistik (bspw. Quartile im Boxplot, Scatterplots, Histogramme) und der Korrelation.
Darauf aufbauend soll im zweiten Teil versucht werden, Abhängigkeiten automatisch zu modellieren und über Kreuzvalidierung zu bewerten. Hierbei ist datengetrieben eine geeignete, möglichst transparente (menschenlesbare) Wissensrepräsentation auszuwählen. Als Anre-gung seien hier Entscheidungsbäume, Regelsysteme, künstliche neuronale Netze und Ent-scheidungslisten genannt. Die Arbeit soll konkrete Wege zur Fortführung der Datenanalyse aufzeigen.
Die besondere Schwierigkeit der Arbeit liegt in der unbekannten Datenqualität, dem Umfang der Daten und insbesondere der Breite des Themas. Zur Verwendung werden Weka, Ra-pidMiner, Gnuplot, Excel, R und Matlab empfohlen.
Kolloquium: 02.10.2008
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Jochen Heinsohn, Christian Kneisel
Download: A1-Poster

Ziel der Arbeit ist die Entwicklung einer Anwendung, die mit Hilfe von überwachtem Lernen und Bildverarbeitung, die von einer Kamera aufgenommenen Objekte erkennt und diese einer Klasse zuordnet. Das Trainieren des Klassifikators soll unter Verwendung einer einfach bedienbaren, grafischen Benutzeroberfläche durchgeführt werden können. Der Anwender hat die Aufgabe, die vom System vorgeschlagene Klassifizierung zu bewerten und gegebenenfalls zu korrigieren. Die während des Trainings entstehenden Klassifikatormodelle sollen dem Anwender dargestellt werden können.
Kolloquium: 29.09.2008
Betreuer: Prof. Dr. F. Mündemann, Dipl.-Inform. I. Boersch
Download: A1-Poster

Ziel der Arbeit ist die Untersuchung der Anwendbarkeit von interaktiver Fitness zur Verbesserung von Cascading Style Sheets durch subjektive Nutzerbewertung in einem evolutionären Optimierungsprozess. Ausgehend von der Fitnessbestimmung in evolutionären Algorithmen sind die Anwendungsindizien, Probleme und insbesondere mögliche Interaktionsvarianten mit dem menschlichen Bewerter darzustellen.
Kolloquium: 29.08.2008
Betreuer: Dipl.-Inform. I. Boersch, Prof. Dr. J. Heinsohn
Download: A1-Poster, Bachelorarbeit

Selbstorganisierende Karten stellen eine besondere Form von künstlichen neuronalen Netzen dar, die sich unüberwacht trainieren lassen. Ziel der Arbeit ist die Konzeption und Implementierung einer Anwendung zum Training von selbstorganisierenden Karten. Schwerpunkt ist hierbei die Darstellung des Lernverlaufs und die Visualisierung der Karte.
Ausgangspunkt der Arbeit sei die vorhandene Applikation SOMARFF [Sch06], die in ihrem Funktionsumfang zu analysieren ist. Die neue Applikation soll den bestehenden Funktionsumfang in den Bereichen Datenvorverarbeitung, Training und Visualisierungen übernehmen und weitere Visualisierungen, wie „P-Matrix“ oder „Karte im Eingaberaum“ enthalten. Zusätzlich soll der Quantisierungsfehler geeignet dargestellt werden.
Wesentliche Eigenschaften selbstorganisierender Karten sollen abstrahiert und austauschbar gestaltet werden, um es zu ermöglichen, neue Topologien, Distanzmetriken, Datenquellen und Nachbarschaftsfunktionen zu integrieren. Besonderer Wert wird dabei auf die Wiederverwendbarkeit von Modulen und Erweiterbarkeit durch neue Module gelegt. Bestandteil der Arbeit ist weiterhin eine aussagekräftige Dokumentation des Systems für Entwickler, eine Nutzeranleitung und der Nachweis der Funktionsfähigkeit des Programms durch geeignete Experimente.
Kolloqium: 31.08.2007
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Jochen Heinsohn
Downloads: A1-Poster Diplomarbeit Applikation Sombrero.zip (84MB)
 Die Idee ist einfach: ein Benutzer benennt für den Computer die Objekte,
die er ihm über die Kamera zeigt, und der Computer versucht
herauszufinden, woran die einzelnen Objekte erkannt werden können, bzw.,
wie sie sich unterscheiden. Wesentliche Freiheitsgrade bestehen hierbei in
der Wahl
Die Idee ist einfach: ein Benutzer benennt für den Computer die Objekte,
die er ihm über die Kamera zeigt, und der Computer versucht
herauszufinden, woran die einzelnen Objekte erkannt werden können, bzw.,
wie sie sich unterscheiden. Wesentliche Freiheitsgrade bestehen hierbei in
der Wahl
Ziel der Arbeit ist die Untersuchung einer automatischen Erzeugung von Bewegungsmustern für gegebene Robotermorphologien am Beispiel des ELFE-Laufroboters. Hierzu ist der Stand der Forschung auf dem Gebiet des maschinellen Lernens sensomotorischer Rückkopplungen mit Gütefunktional, die möglichen Repräsentationen von Bewegungsmustern und deren Lernalgorithmen im Überblick darzustellen.
Der Schwerpunkt der Arbeit liegt in der Untersuchung der Anwendung von Evolutionären Algorithmen, insbesondere Genetischem Programmieren auf die Problemstellung. Die gewonnenen Erkenntnisse sind in ein prototypisches System mit einem realen Roboter umzusetzen. Hierbei ist auf Modularisierung und die Möglichkeit zur Weiterentwicklung Wert zu legen. Wenn möglich, sollten Hypothesen über den Evolutionsverlauf am realen System aus einer Simulation abgeleitet und im Experiment evaluiert werden.
Abgabe: 29.11.2006 Kolloqium: 18.12.2006
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Jochen Heinsohn
Downloads: Diplomarbeit A1-Poster
Ziel der Arbeit ist die Untersuchung von Visualisierungsmöglichkeiten von Daten mit Hilfe von Selbstorganisierenden Karten. Hierbei sind sowohl musterbezogene als auch musterunabhängige Varianten zu betrachten. Die Verfahren sollen prototypisch in ein Programmsystem umgesetzt werden, welches ohne Installation über das Netz nutzbar ist. Der Lernprozess ist geeignet darzustellen.
Hierzu sind Selbstorganisierende Karten im theoretischen Überblick zu beleuchten und für den Schwerpunkt Visualisierung trainierter Karten zu vertiefen. Anhand der im Verlauf der Diplomarbeit erzielten praktischen und theoretischen Erkenntnisse soll eine Bewertung und Systematisierung der Visualisierungsvarianten erstellt werden. Dabei sollen Aspekte wie Lesbarkeit, Informationsgehalt, Umsetzungskomplexität und andere Kriterien beurteilt werden.
Abgabe: 03.03.2006 Kolloqium: 07.04.2006
Betreuer: Dipl.-Inform. Ingo Boersch, Prof. Dr.-Ing. Jochen Heinsohn
Downloads: A1-Poster Diplomarbeit Vortrag

Um ein Gesicht in einem Bild automatisch zu verarbeiten (Identifikation, Verifikation usw.), ist es notwendig zu wissen, ob und wo sich ein Gesicht im Bild befindet. Dieser als Gesichtsdetektion bezeichnete Vorgang kann mit verschiedenen Ansätzen realisiert werden.
In dieser Arbeit sollte ein Verfahren entwickelt werden, welches Gesichtsmerkmale (Augen, Nase und Mund) in Einzelbildern detektieren kann. Das Gesicht sollte sich dabei in der Frontalansicht befinden und beliebig positioniert, skaliert und rotiert sein dürfen. Weiterhin sollte eine beliebige Anzahl desselben Gesichtsmerkmals (z.B. des rechten Auges) erlaubt und das Verfahren Beleuchtungsinvariant sein.
Um das gesamte Gesicht zu detektieren, müssen die einzelnen Gesichtsmerkmale anschließend kombiniert werden, was jedoch nicht Gegenstand dieser Arbeit war.
Abgabe: 08.11.2005 Kolloqium: 07.12.2005
Betreuer: Prof. Dr. rer. nat. Friedhelm Mündemann, Dipl.-Inform. Ingo Boersch
Downloads: Diplomarbeit A!-Poster

Computer vision is a computer science field belonging to artificial intelligence. The purpose of this branch is allowing computers to understand the physical world by visual media means. This document proposes an artificial neural network based face detection system. It detects frontal faces in RGB images and is relatively light invariant.
Problem description and definition are enounced in the first sections; then the neural network training process is discussed and the whole process is proposed; finally, practical results and conclusions are discussed. Process has three stages: 1) Image preprocessing, 2) Neural network classifying, 3) Face number reduction. Skin color detection and Principal Component Analysis are used in preprocessing stage; back propagation neural network is used for classifying and a simple clustering algorithm is used on the reduction stage.
Abgabe: 12.09.2005
Betreuer: Dipl.-Inform. Ingo Boersch
Downloads: Studienarbeit

Relating to this text
During the last years of my career, the main intention of my work has been to apply neural networks to several fields of my interest, mainly networking security and biomedicine. As Dr. Carmen Paz Suárez Araujo’s, from University of Las Palmas de Gran Canaria (Spain), and Prof. Ingo Boersch’s, from Fachhochschule Brandenburg (Germany), undergraduate student I have learned how important the neurocomputing is becoming in nowadays engineering tasks. Through this path, I have gathered a variety of ideas and problems which I would have appreciated to be written or explicitly available for my personal reading and further understanding.
The employment of a simulator to develop first stage analysis and to plan further work is a must in the engineering discipline. My aim in the development of this brief textbook has been to compose a little, but well condensed manual, where the reader can get the point of self organized networks, and moreover, of Kohonen Self Organized Maps, SOM. Using JNNS, the reader will be able to apply the theoretical issues of
Kohonen networks into practical and real development of ideas.
This brief textbook is oriented to those with little experience in self organization and Kohonen networks, but also to those interested in using and analyzing the deployment of solutions with the Java Neural Network Simulator, JNNS.
Abgabe: 07.09.2005
Betreuer: Dipl.-Inform. Ingo Boersch
Downloads: Studienarbeit Patternfiles.zip

With the growth of computer networks in the recent years, security has become a crucial aspect in modern computer systems. An adequate way to detect systems misuse is based on monitoring users’ activities and network traffic. Several intrusion detection methods have been proposed but they result in an expensive implementation and doubtful yield.
In this paper, it is analyzed an approach based on the application of non-supervised auto-organizing artificial neural networks to improve the performance of real-time intrusion detection systems.
Abgabe: 08.07.2005
Betreuer: Dipl.-Inform. Ingo Boersch
Downloads: Studienarbeit

 Der Umfang des Versuchsaufbaus war für ein Projekt zu groß, so dass als
wesentliches Projektergebnis der Versuchsaufbau in Hard- und Software
realisiert wurde. Es können damit automatisch Individuen im
Evolutionsprozess erzeugt und auf der ELFE evaluiert werden.
Der Umfang des Versuchsaufbaus war für ein Projekt zu groß, so dass als
wesentliches Projektergebnis der Versuchsaufbau in Hard- und Software
realisiert wurde. Es können damit automatisch Individuen im
Evolutionsprozess erzeugt und auf der ELFE evaluiert werden.

Ziel der Arbeit ist eine Untersuchung zur automatischen Erstellung von Objektbeschreibungen aus vorgegebenen Quellbildern.
Die Objektbeschreibung erfolgt in Form von L-Systemen, die passend zu Quellbildern erzeugt werden. Hierzu wird ein evolutionärer Prozeß auf die L-Systeme angewendet. Fitnessfunktion sei die Übereinstimmung der Ansichten der erzeugten L-Systeme aus verschiedenen Kameraperspektiven mit den Originalbildern eines einfachen Gegenstandes.
Die Arbeit soll die theoretischen Grundlagen dieses Ansatzes darlegen (insbesondere Einordnung und Klassifizierung von L-Systemen und ihre Evolutionsmöglichkeiten), eine Systemarchitektur vorschlagen und in Teilen prototypisch implementieren.
Bei der Implementation soll besonderer Wert auf die Weiternutzbarkeit der erstellten Module und die Definition externer Schnittstellen gelegt werden. Die Funktionsfähigkeit des Systems ist durch geeignete Teststellungen zu evaluieren.
Abgabe: 14.06.2004 Kolloqium: 29.06.2004
Betreuer: Prof. Dr. rer. nat. Friedhelm Mündemann, Dipl.-Inform. Ingo Boersch
Downloads: A1-Poster Diplomarbeit Vortrag

Bei der SAFE Wachschutz / Allservice Brandenburg GmbH ist man daran interessiert, die Tourenplanung für das Wachpersonal so effektiv wie möglich zu gestalten, um Zeit und Kosten zu sparen.
Das Problem stellt sich wie folgt dar: ausgehend von einem zentralen Fahrzeugdepot müssen mehrere Kunden (Wachobjekte) angefahren und kontrolliert werden. Dazu stehen im Depot mehrere Fahrzeuge zur Verfügung.
Ziel ist es, die verschiedenen Kunden auf mehrere Routen so aufzuteilen, dass die dafür benötigte Zeit und Gesamtstrecke möglichst minimal werden. Die Planung der einzelnen Touren soll durch ein rechnergestütztes Verfahren vorgenommen werden. Dazu ist eine Software-Lösung zu erstellen, welche die individuellen Anforderungen des Problems in geeigneter Art und Weise abbildet und unter Berücksichtigung sämtlicher Restriktionen möglichst effiziente Routen ermittelt.
Teilaufgaben:
Das Programm soll an einem konkreten Beispiel (Nachtrevier Brandenburg) getestet und die Lösungen bzgl. des Zeit- und Kostenaufwands mit den bisherigen Fahrtrouten verglichen werden.
Abgabe: 04.02.2003 Kolloqium: 11.03.2003
Betreuer: Prof. Dr.-Ing. Jochen Heinsohn, Jörn Schlanert (Geschäftsführer SAFE Wachschutz / Allservice GmbH)
Downloads: Diplomarbeit A1-Poster Vortrag

Zielstellung des Themas ist die Konzeption eines Systems zur Verfolgung von Objekten in Bildfolgen. Dieses System gibt bei Anfragen an die Wissensbasis Auskunft über die möglichen Positionen der Objekte, auch wenn diese zum aktuellen Zeitpunkt von anderen Objekten verdeckt sind. Systembedingt (z.B. Verdeckung) kann die Position eines Objektes mehrdeutig sein, hierbei sind alle möglichen Positionen des Objektes unter bestimmten Randbedingungen zu verfolgen.
In der Arbeit sollen die Grundlagen für die Wissensrepräsentation räumlicher Relationen sowie des Inferenzprozesses untersucht, sowie eine Systemarchitekur für das Gesamtsystem entwickelt werden. Die Funktionalität wird über eine protoypische Implemetation der Architektur (ohne Bildaufnahme, -verarbeitung) nachgewiesen. Die Umsetzung soll besonderen Wert auf Modularisierung und Wiederverwendbarkeit legen.
Abgabe: 22.11.2002 Kolloqium: 15.01.2003
Betreuer: Prof. Dr.-Ing. Jochen Heinsohn, Dipl.-Inform Ingo Boersch
Downloads: Diplomarbeit A1-Poster Vortrag

Für die Tourenplanung innerhalb der Entsorgungs- und Baubranche sollen moderne Constrainttechniken analysiert und eine Softwarebibliothek entwickelt worden. Hierzu solIte der Stand der Forschung auf den Gebieten der "Constraint-Satisfaction" und von "Constraint Systemen" einfließen und bei der Analyse der Fahrzeugplanung hinsichtlich der Anforderungen an die zu schaffende Softwarebibliothek beachtet worden.
Für die Arbeit sollten geeignete Constraint-Solver-Bibliotheken hinsichtlich des Fahrzeugroutens evaluiert und ein zweckmäßiger Constraint-Solver ausgewählt werden.
Unter Einbeziehung des gewählten Solvers stand es zur Aufgabe, eine Softwarebibliothek zu entwerfen und zu implementieren, die gegebene "Pickup and Delivery" Probleme 1öst. Die Implementierung sollte in C/C++ oder in Delphi (Objektpascal) durchgeführt werden. Dabei war zu beachten, dass die entwickelte Bibliothek von Delphi-Programmen aus nutzbar und auf dem Betriebsystem Windows NT 4 lauffähig sein musste.
Abgabe: 22.04.2002 Kolloqium: 25.06.2002
Betreuer: Prof. Dr.-Ing. Jochen Heinsohn, Dipl.-Ing (FH) Torsion Storrer (IVU Traffic Technologies AG)
Downloads: Diplomarbeit A1-Poster Vortrag
Zielstellung des Themas ist die Evaluation des Reinforcement-Lernens (speziell Q-Lernen) zur Anwendung in mobilen Systemen. Hierbei sollen die verschiedenen Arten der Methode theoretisch und experimentell verglichen und beispielhaft im Simulator sowie im realen Roboter umgesetzt werden. Die Anwendungsdomäne sei dabei das Erlernen eines Verhaltens zur Hindernisvermeidung mittels Sonarsensoren. Die Implementierung soll besonderen Wert auf die Wiedernutzbarkeit legen.
Abgabe: 10.01.2002 Kolloqium: 31.01.2002
Betreuer: Prof. Dr.-Ing. Jochen Heinsohn, Dipl.-Inform Ingo Boersch
Downloads: Diplomarbeit A1-Poster Vortrag

Sperrt man 4-Gewinnt-Programme in eine Box und startet eine Reproduktion und Selektion durch gegenseitiges Bespielen - steigt dann die Fitness der Spielprogramme? Wie kann die Fitness von Spielprogrammen absolut gemessen werden? Diese Fragen haben wir in diesem Projekt im WS01/02 beantwortet.
 How can computers learn to solve problems without being explicitly
programmed?
How can computers learn to solve problems without being explicitly
programmed?
